import pyarrow.dataset as ds
import numpy as np
import pandas as pd19 Parquet and Arrow
19.1 Learning Objectives
- The difference between column major and row major data
- Speed advantages to columnnar data storage
- How
arrowenables faster processing
19.2 Introduction
Paralleization is great, and can greatly help you in working with large data. However, it might not help you with every processing problem. Like we talked about with Dask, sometimes your data are too large to be read into memory, or you have I/O limitations. Parquet and pyarrow are newer, powerful tools that are designed to help overcome some of these problems. pyarrow and Parquet are newer technologies, and are a bit on the ‘bleeding edge’, but there is a lot of excitement about the possibility these tools provide.
Before jumping into those tools, however, first let’s discuss system calls. These are calls that are run by the operating system within their own process. There are several that are relevant to reading and writing data: open, read, write, seek, and close. Open establishes a connection with a file for reading, writing, or both. On open, a file offset points to the beginning of the file. After reading or writing n bytes, the offset will move n bytes forward to prepare for the next opration. Read will read data from the file into a memory buffer, and write will write data from a memory buffer to a file. Seek is used to change the location of the offset pointer, for either reading or writing purposes. Finally, close closes the connection to the file.
If you’ve worked with even moderately sized datasets, you may have encounted an “out of memory” error. Memory is where a computer stores the information needed immediately for processes. This is in contrast to storage, which is typically slower to access than memory, but has a much larger capacity. When you open a file, you are establishing a connection between your processor and the information in storage. On read, the data is read into memory that is then available to your python process, for example.
So what happens if the data you need to read in are larger than your memory? My brand new M1 MacBook Pro has 16 GB of memory, but this would be considered a modestly sized dataset by this courses’s standards. There are a number of solutions to this problem, which don’t involve just buying a computer with more memory. In this lesson we’ll discuss the difference between row major and column major file formats, and how leveraging column major formats can increase memory efficiency. We’ll also learn about another python library called pyarrow, which has a memory format that allows for “zero copy” read.
19.3 Row major vs column major
The difference between row major and column major is in the ordering of items in the array when they are read into memory.
Take the array:
a11 a12 a13
a21 a22 a23This array in a row-major order would be read in as:
a11, a12, a13, a21, a22, a23
You could also read it in column-major order as:
a11, a21, a12, a22, a13, a33
By default, C and SAS use row major order for arrays, and column major is used by Fortran, MATLAB, R, and Julia.
Python uses neither, instead representing arrays as lists of lists, though numpy uses row-major order.
19.3.1 Row major versus column major files
The same concept can be applied to file formats as the example with arrays above. In row-major file formats, the values (bytes) of each record are read sequentially.
| Name | Location | Age |
|---|---|---|
| John | Washington | 40 |
| Mariah | Texas | 21 |
| Allison | Oregon | 57 |
In the above row major example, data are read in the order: John, Washingon, 40 \n Mariah, Texas, 21.
This means that getting a subset of rows with all the columns would be easy; you can specify to read in only the first X rows (utilizing the seek system call). However, if we are only interested in Name and Location, we would still have to read in all of the rows before discarding the Age column.
If these data were organized in a column major format, they might look like this:
Name: John, Mariah, Allison
Location: Washington, Texas, Oregon
Age: 40, 21, 57And the read order would first be the names, then the locations, then the age. This means that selecting all values from a set of columns is quite easy (all of the Names and Ages, or all Names and Locations), but reading in only the first few records from each column would require reading in the entire dataset. Another advantage to column major formats is that compression is more efficient since compression can be done across each column, where the data type is uniform, as opposed to across rows with many data types.
19.4 Parquet
Parquet is an open-source binary file format that stores data in a column-major format. The format contains several key components:
- row group
- column
- page
- footer
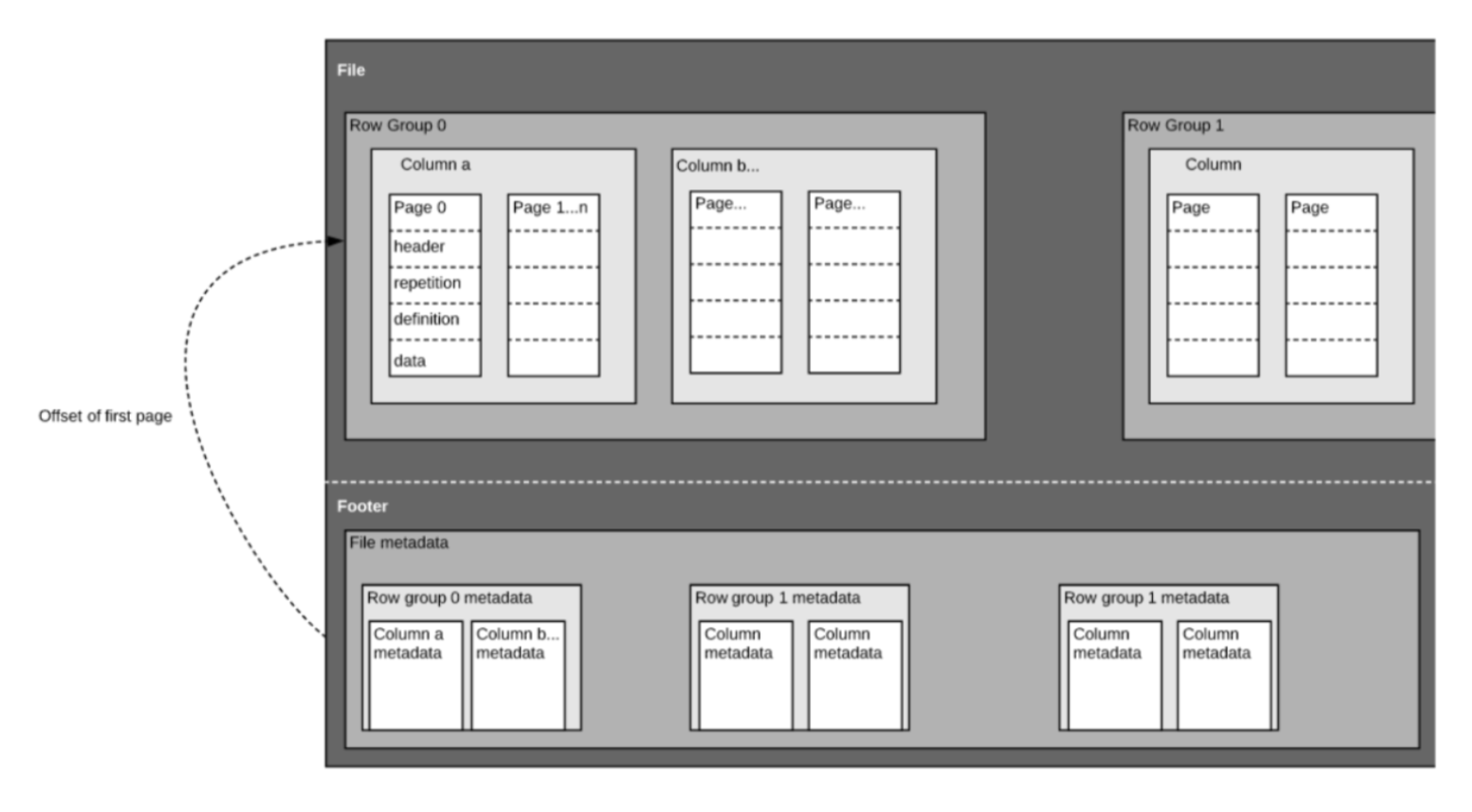
Row groups are blocks of data over a set number of rows that contain data from the same columns. Within each row group, data are organized in column-major format, and within each column are pages that are typically 1MB. The footer of the file contains metadata like the schema, encodings, unique values in each column, etc.
The parquet format has many tricks to to increase storage efficiency, and is increasingly being used to handle large datasets.
19.5 Arrow
So far, we have discussed the difference between organizing information in row-major and column-major format, how that applies to arrays, and how it applies to data storage on disk using Parquet.
Arrow is a language-agnostic specification that enables representation of column-major information in memory without having to serialize data from disk. The Arrow project provides implementation of this specification in a number of languages, including Python.
Let’s say that you have utilized the Parquet data format for more efficient storage of your data on disk. At some point, you’ll need to read that data into memory in order to do analysis on it. Arrow enables data transfer between the on disk Parquet files and in-memory Python computations, via the pyarrow library.
pyarrow is great, but relatively low level. It supports basic group by and aggregate functions, as well as table and dataset joins, but it does not support the full operations that pandas does.
19.6 Example
In this example, we’ll read in a dataset of fish abundance in the San Francisco Estuary, which is published in csv format on the Environmental Data Initiative. This dataset isn’t huge, but it is big enough (3 GB) that working with it locally can be fairly taxing on memory. Motivated by user difficulties in actually working with the data, the deltafish R package was written using the R implementation of arrow. It works by downloading the EDI repository data, writing it to a local cache in parquet format, and using arrow to query it. In this example, I’ve put the Parquet files in a sharable location so we can explore them using pyarrow.
First, we’ll load the modules we need.
Next we can read in the data using ds.dataset(), passing it the path to the parquet directory and how the data are partitioned.
deltafish = ds.dataset("/home/shares/deltafish/fish",
format="parquet",
partitioning='hive')You can check out a file listing using the files method. Another great feature of parquet files is that they allow you to partition the data accross variables of the dataset. These partitions mean that, in this case, data from each species of fish is written to it’s own file. This allows for even faster operations down the road, since we know that users will commonly need to filter on the species variable. Even though the data are partitioned into different files, pyarrow knows that this is a single dataset, and you still work with it by referencing just the directory in which all of the partitioned files live.
deltafish.files['/home/shares/deltafish/fish/Taxa=Acanthogobius flavimanus/part-0.parquet',
'/home/shares/deltafish/fish/Taxa=Acipenser medirostris/part-0.parquet',
'/home/shares/deltafish/fish/Taxa=Acipenser transmontanus/part-0.parquet',
'/home/shares/deltafish/fish/Taxa=Acipenser/part-0.parquet'...You can view the columns of a dataset using schema.to_string()
deltafish.schema.to_string()SampleID: string
Length: double
Count: double
Notes_catch: string
Species: stringIf we are only interested in a few species, we can do a filter:
expr = ((ds.field("Taxa")=="Dorosoma petenense")|
(ds.field("Taxa")=="Morone saxatilis") |
(ds.field("Taxa")== "Spirinchus thaleichthys"))
fishf = deltafish.to_table(filter = expr,
columns =['SampleID', 'Length', 'Count', 'Taxa'])There is another dataset included, the survey information. To do a join, we can just use the join method on the arrow dataset.
First read in the survey dataset.
survey = ds.dataset("/home/jclark/deltafish/survey",
format="parquet",
partitioning='hive')Take a look at the columns again:
survey.schema.to_string()Let’s pick out only the ones we are interested in.
survey_s = survey.to_table(columns=['SampleID','Datetime', 'Station', 'Longitude', 'Latitude'])Then do the join, and convert to a pandas data.frame.
fish_j = fishf.join(survey_s, "SampleID").to_pandas()Note that when we did our first manipulation of this dataset, we went from working with a FileSystemDataset, which is a representation of a dataset on disk without reading it into memory, to a Table, which is read into memory. pyarrow has a number of functions that do computations on datasets without reading them into memory. However these are evaluated “eagerly,” as opposed to “lazily.” These are useful in some cases, like above, where we want to take a larger than memory dataset and generate a smaller dataset (via filter, or group by/summarize), but are not as useful if we need to do a join before our summarization/filter.
More functionality for lazy evaluation is on the horizon for pyarrow though, by leveraging Ibis.
19.7 Synopsis
In this lesson we learned:
- the difference between row major and column major formats
- under what circumstances a column major data format can improve memory efficiency
- how
pyarrowcan interact with Parquet files to analyze data