Learning Objectives
- Understand the importance of data management for successfully preserving data
- Learn about metadata guidelines and best practices for reproducibility
- Become familiar with environmental data repositories for accessing and publishing data
5.1 The Big Idea
The ultimate goal of this lesson is to provide an overview of a reproducible open science framework for your research, when either you are accessing published data (data user) to – for example use it for synthesis or you want to publish your own data (data author). To achieve this, we are going to talk about the following topics.
- The Data Life Cycle
- The importance of data management
- Metadata best practices
- Data preservation
We will discuss how these topics relate to each other and why they are the building block for you to use others’ data and for others to access, interpret, and use your data in the future.
5.2 The Data Life Cycle
The Data Life Cycle gives you an overview of meaningful steps in a research project. This step-by-step breakdown facilitates successful management and preservation of data throughout a project. Some research activities might use only part of the life cycle. For example, a meta-analysis might focus on the Discover, Integrate, and Analyze steps, while a project focused on primary data collection and analysis might bypass the Discover and Integrate steps.
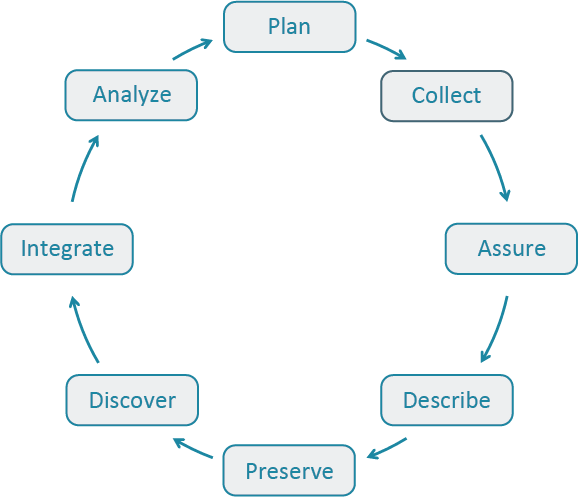
The first step to working with data is identifying where my project is starting in the Data Life Cycle. Using the data life cycle stages, create your own cycle that best fits your project needs.
A way to use the Data Life Cycle in practice is to:
- Think about the end goal, outcomes, and products of your project
- Think and decide steps in the Data Life Cycle you need to include in your project
- Review best practices for that step in the cycle and start outlining action items in each of those steps.
DataOne’s Data Management Skillbuilding Hub offers several best practices on how to effectively work with your data throughout all stages of the data life cycle.
No matter how your data life cycle looks like, Plan should be at the top of the cycle. It is advisable to initiate your data management planning at the beginning of your research process before any data has been collected or discovered. The following section will discuss more in-depth data management and how to plan accordingly
5.3 Managing your data
Successfully managing your data throughout a research project helps ensures its preservation for future use.
5.3.1 Why manage your data?
From a Researcher Perspective
- Keep yourself organized – be able to find your files (data inputs, analytic scripts, outputs at various stages of the analytic process, etc.)
- Track your science processes for reproducibility – be able to match up your outputs with exact inputs and transformations that produced them
- Better control versions of data – easily identify versions that can be periodically purged
- Quality control your data more efficiently
- To avoid data loss (e.g. making backups)
- Format your data for re-use (by yourself or others)
- Be prepared: Document your data for your own recollection, accountability, and re-use (by yourself or others)
- Gain credibility and recognition for your science efforts through data sharing!
Advancement of Science
Data is a valuable asset – it is expensive and time consuming to collect
Maximize the effective use and value of data and information assets
Continually improve the quality including: data accuracy, integrity, integration, timeliness of data capture and presentation, relevance, and usefulness
Ensure appropriate use of data and information
Facilitate data sharing
Ensure sustainability and accessibility in long term for re-use in science
5.3.2 Tools to Manage your Data
A Data Management Plan (DMP) is a document that describes how you will use your data during a research project, as well as what you will do with your data long after the project ends. DMPs are living documents and should be updated as research plans change to ensure new data management practices are captured (Environmental Data Initiative).
A well-thought-out plan means you are more likely to:
- stay organized
- work efficiently
- truly share data
- engage your team
- meet funder requirements as DMPs are becoming common in the submission process for proposals
A DMP is both a straightforward blueprint for how you manage your data, and provides guidelines for your and your team on policies, access, roles, and more. While it is important to plan, it is equally important to recognize that no plan is perfect as change is inevitable. To make your DMP as robust as possible, treat it as a “living document” that you periodically review with your team and adjust as the needs of the project change.
5.3.3 How to Plan
- Plan early: research shows that over time, information is lost and this is inevitable so it’s important to think about long-term plans for your research at the beginning before you’re deep in your project. And ultimately, you’ll save more time.
- Plan in collaboration: high engagement of your team and other important contributors is not only a benefit to your project, but it also makes your DMP more resilient. When you include diverse expertise and perspectives to the planning stages, you’re more likely to overcome obstacles in the future.
- Utilize existing resources: don’t reinvent the wheel! There are many great DMP resources out there. Consider the article Ten Simple Rules for Creating a Good Data Management Plan (Michener 2015), which has succinct guidelines on what to include in a DMP. Or use an online tool like DMPTool, which provides official DMP templates from funders like NSF, example answers, and allows for collaboration.
- Make revising part of the process: Don’t let your DMP collect dust after your initially write it. Make revising the DMP part of your research project and use it as a guide to ensure you’re keeping on track.
- Include tidy and ethical lens: It is important to start thinking through these lenses during the planning process of your DMP, it will make it easier to include and maintain tidy and ethical principles throughout the entire project. We will discuss in depth about tidy data, FAIR principles and data ethics though the CARE principles later this week.
More details on what to include in a Data Management Plan in Additional Resources
5.4 Metadata Best Practices
Within the data life cycle you can be collecting data (creating new data) or integrating data that has all ready been collected. Either way, metadata plays plays a major role to successfully spin around the cycle because it enables data reuse long after the original collection.
Imagine that you’re writing your metadata for a typical researcher (who might even be you!) 30+ years from now - what will they need to understand what’s inside your data files?
The goal is to have enough information for the researcher to understand the data, interpret the data, and then reuse the data in another study.
5.4.1 Overall Guidelines
Another way to think about metadata is to answer the following questions with the documentation:
- What was measured?
- Who measured it?
- When was it measured?
- Where was it measured?
- How was it measured?
- How is the data structured?
- Why was the data collected?
- Who should get credit for this data (researcher AND funding agency)?
- How can this data be reused (licensing)?
5.4.2 Bibliographic Guidelines
The details that will help your data be cited correctly are:
- Global identifier like a digital object identifier (DOI)
- Descriptive title that includes information about the topic, the geographic location, the dates, and if applicable, the scale of the data
- Descriptive abstract that serves as a brief overview off the specific contents and purpose of the data package
- Funding information like the award number and the sponsor
- People and organizations like the creator of the dataset (i.e. who should be cited), the person to contact about the dataset (if different than the creator), and the contributors to the dataset
5.4.3 Discovery Guidelines
The details that will help your data be discovered correctly are:
- Geospatial coverage of the data, including the field and laboratory sampling locations, place names and precise coordinates
- Temporal coverage of the data, including when the measurements were made and what time period (ie the calendar time or the geologic time) the measurements apply to
- Taxonomic coverage of the data, including what species were measured and what taxonomy standards and procedures were followed
- Any other contextual information as needed
5.4.4 Interpretation Guidelines
The details that will help your data be interpreted correctly are:
- Collection methods for both field and laboratory data the full experimental and project design as well as how the data in the dataset fits into the overall project
- Processing methods for both field and laboratory samples
- All sample quality control procedures
- Provenance information to support your analysis and modelling methods
- Information about the hardware and software used to process your data, including the make, model, and version
- Computing quality control procedures like testing or code review
5.4.5 Data Structure and Contents
- Everything needs a description: the data model, the data objects (like tables, images, matrices, spatial layers, etc), and the variables all need to be described so that there is no room for misinterpretation.
- Variable information includes the definition of a variable, a standardized unit of measurement, definitions of any coded values (i.e. 0 = not collected), and any missing values (i.e. 999 = NA).
Not only is this information helpful to you and any other researcher in the future using your data, but it is also helpful to search engines. The semantics of your dataset are crucial to ensure your data is both discoverable by others and interoperable (that is, reusable).
For example, if you were to search for the character string “carbon dioxide flux” in a data repository, not all relevant results will be shown due to varying vocabulary conventions (i.e., “CO2 flux” instead of “carbon dioxide flux”) across disciplines — only datasets containing the exact words “carbon dioxide flux” are returned. With correct semantic annotation of the variables, your dataset that includes information about carbon dioxide flux but that calls it CO2 flux WOULD be included in that search.
5.4.6 Rights and Attribution
Correctly assigning a way for your datasets to be cited and reused is the last piece of a complete metadata document. This section sets the scientific rights and expectations for the future on your data, like:
- Citation format to be used when giving credit for the data
- Attribution expectations for the dataset
- Reuse rights, which describe who may use the data and for what purpose
- Redistribution rights, which describe who may copy and redistribute the metadata and the data
- Legal terms and conditions like how the data are licensed for reuse.
5.4.7 Metadata Standards
So, how does a computer organize all this information? There are a number of metadata standards that make your metadata machine readable and therefore easier for data curators to publish your data.
- Ecological Metadata Language (EML)
- Geospatial Metadata Standards (ISO 19115 and ISO 19139)
- Biological Data Profile (BDP)
- Dublin Core
- Darwin Core
- PREservation Metadata: Implementation Strategies (PREMIS)
- Metadata Encoding Transmission Standard (METS)
Note this is not an exhaustive list.
5.4.8 Data Identifiers
Many journals require a DOI (a digital object identifier) be assigned to the published data before the paper can be accepted for publication. The reason for that is so that the data can easily be found and easily linked to.
Some data repositories assign a DOI for each dataset you publish on their repository. But, if you need to update the datasets, check the policy of the data repository. Some repositories assign a new DOI after you update the dataset. If this is the case, researchers should cite the exact version of the dataset that they used in their analysis, even if there is a newer version of the dataset available.
5.4.9 Data Citation
Researchers should get in the habit of citing the data that they use (even if it’s their own data!) in each publication that uses that data.
5.5 Data Sharing & Preservation
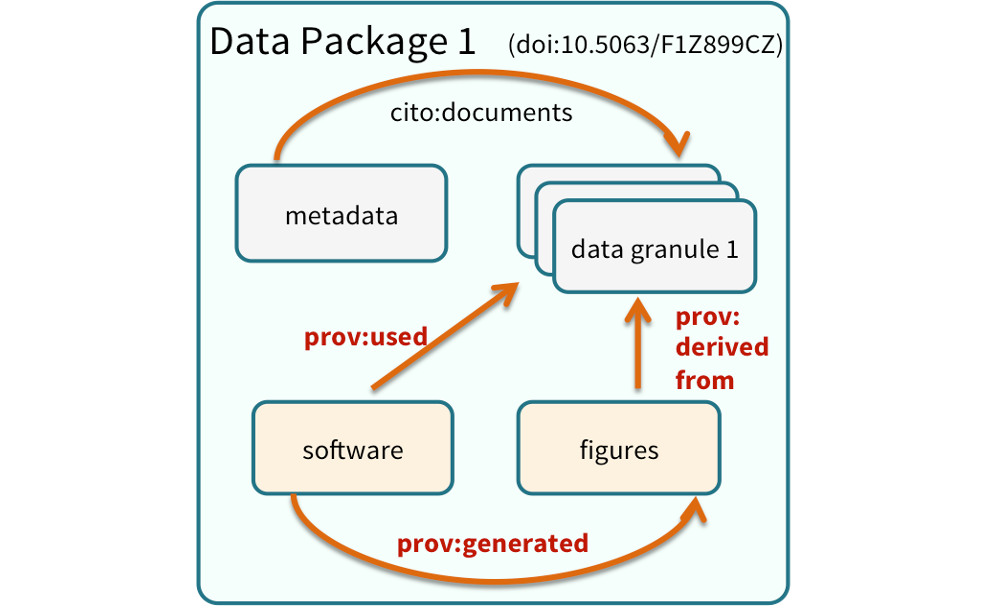
5.5.1 Data Packages
We define a data package as a scientifically useful collection of data and metadata that a researcher wants to preserve.
Sometimes a data package represents all of the data from a particular experiment, while at other times it might be all of the data from a grant, or on a topic, or associated with a paper. Whatever the extent, we define a data package as having one or more data files, software files, and other scientific products such as graphs and images, all tied together with a descriptive metadata document.
Many data repositories assign a unique identifier to every version of every data file, similarly to how it works with source code commits in GitHub. Those identifiers usually take one of two forms. A DOI identifier, often assigned to the metadata and becomes a publicly citable identifier for the package. Each of the other files gets a global identifier, often a UUID that is globally unique. This allows to identify a digital entity within a data package.
In the graphic to the side, the package can be cited with the DOI doi:10.5063/F1Z1899CZ,and each of the individual files have their own identifiers as well.
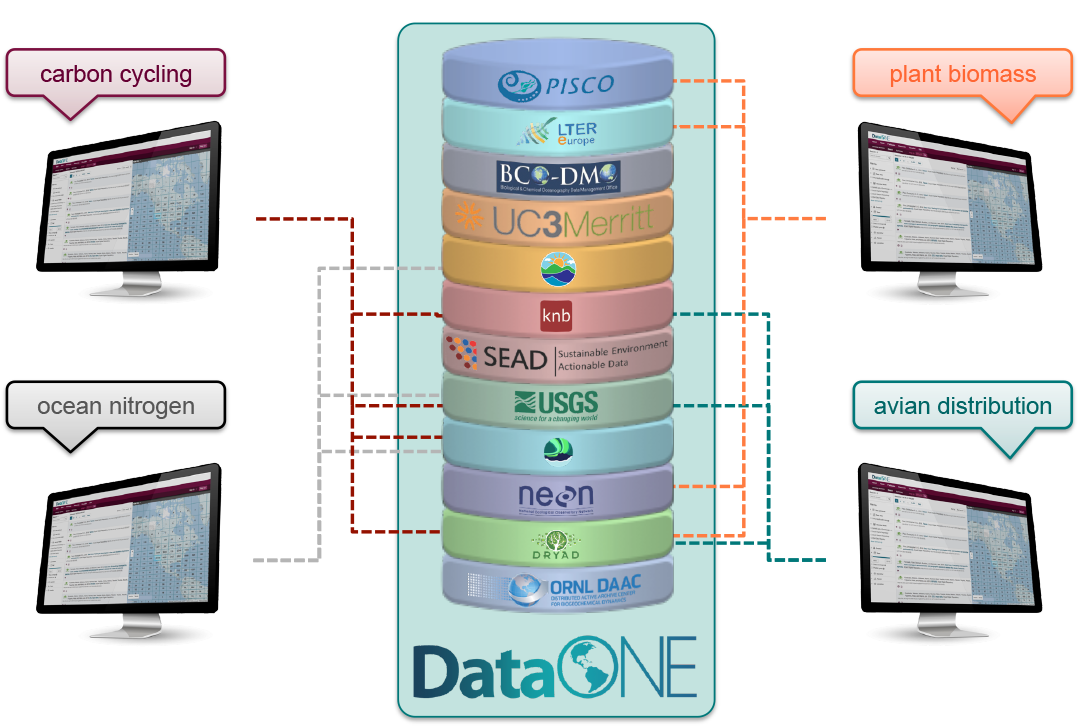
5.5.2 Data Repositories: Built for Data (and code)
- GitHub is not an archival location
- Examples of dedicated data repositories:
- KNB
- Arctic Data Center
- tDAR
- EDI
- Zenodo
- Dedicated data repositories are:
- Rich in metadata
- Archival in their mission
- Certified
- Data papers, e.g., Scientific Data
- re3data is a global registry of research data repositories
- Repository Finder is a pilot project and tool to help researchers find an appropriate repository for their work
5.5.2.1 DataOne Federation
DataONE is a federation of dozens of data repositories that work together to make their systems interoperable and to provide a single unified search system that spans the repositories. DataONE aims to make it simpler for researchers to publish data to one of its member repositories, and then to discover and download that data for reuse in synthetic analyses.
DataONE can be searched on the web, which effectively allows a single search to find data from the dozens of members of DataONE, rather than visiting each of the (currently 44!) repositories one at a time.
5.6 Summary
- The Data Life Cycle help us see the big picture of our data project.
- Once we identify the necessary steps it is helpful to think through each one and plan accordingly.
- It is extremely helpful to develop a data management plan is to stay organized.
- Document everything. Having rich metadata is a key factor to enable data reuse. Describe your data and files and use an appropriate metadata standard.
- Publish your data in a stable long live repository and assign a unique identifier.
5.7 Data Users Example
Data Life Cycle
Plan
Discover: Finding and understanding data
Integrate: Accessing Data
Analyze
Describe: Metadata, Citing data (provenance)
Preserve: Publishing a derived data package
5.8 Exercise: Evaluate a Data Package on the EDI Repository
Explore data packages published on EDI assess the quality of their metadata. Imagine you are planning on using this data for a synthesis project.
Break into groups and use the following data packages:
You and your group will evaluate a data package for its: (1) metadata quality, and (2) data documentation quality for reusability.
- Open our Data Package Assessment Rubric (Note: Evaluate only the Metadata Documentation and Quality section), make copy and:
- Investigate the metadata in the provided data
- Does the metadata meet the standards we talked about? How so?
- If not, how would you improve the metadata based on the standards we talked about?
- Investigate the overall data documentation in the data package
- Is the documentation sufficient enough for reusing the data? Why or why not?
- If not, how would you improve the data documentation? What’s missing?
- Investigate the metadata in the provided data
- Elect someone to share back to the group the following:
- How easy or challenging was it to find the metadata and other data documentation you were evaluating? Why or why not?
- What documentation stood out to you? What did you like or not like about it?
- Do you feel like you understand the research project enough to use the data yourself (aka reproducibility?
If you and your group finish early, check out more datasets in the bonus question.
5.9 Bonus: Investigate metadata and data documentation in other Data Repositories
Not all environmental data repositories document and publish datasets and data packages in the same way. Nor do they have the same submission requirements. It’s helpful to become familiar with metadata and data documentation jargon so it’s easier to identify the information you’re looking for. It’s also helpful for when you’re nearing the end of your project and are getting ready to publish your datasets.
Evaluate the following data packages at these data repositories:
- KNB Arthropod pitfall trap biomass captured (weekly) and pitfall biomass model predictions (daily) near Toolik Field Station, Alaska, summers 2012-2016
- DataOne USDA-NOAA NWS Daily Climatological Data
- Arctic Data Center Landscape evolution and adapting to change in ice-rich permafrost systems 2021-2022
How different are these data repositories from the EDI Data Portal? Would you consider publishing you data at one or multiple of these repositories?
5.10 Additional Resouces
5.10.1 What to include in a DMP
| DMP Section | Guiding Questions |
|---|---|
| Funder Requirements |
|
| Study Design |
|
| Data Collection |
|
| Data Organization |
|
| Quality Assurance and Quality Control |
|
| Data Policies |
|
| Data documentation & Metadata |
|
| Data Sharing |
|
| Roles and Responsibilities |
|
| Long-term Storage & Data Preservation |
|
| Budget |
|