library(qualtRics)
library(tidyr)
library(knitr)
library(ggplot2)
library(kableExtra)
library(dplyr)Learning Objectives
- Overview of survey tools
- Generating a reproducible survey report with Qualtrics
13.1 Introduction
Surveys and questionnaires are commonly used research methods within social science and other fields. For example, understanding regional and national population demographics, income, and education as part of the National Census activity, assessing audience perspectives on specific topics of research interest (e.g. the work by Tenopir and colleagues on Data Sharing by Scientists), evaluation of learning deliverable and outcomes, and consumer feedback on new and upcoming products. These are distinct from the use of the term survey within natural sciences, which might include geographical surveys (“the making of measurement in the field from which maps are drawn”), ecological surveys (“the process whereby a proposed development site is assess to establish any environmental impact the development may have”) or biodiversity surveys (“provide detailed information about biodiversity and community structure”) among others.
Although surveys can be conducted on paper or verbally, here we focus on surveys done via software tools. Needs will vary according to the nature of the research being undertaken. However, there is fundamental functionality that survey software should provide including:
- The ability to create and customize questions
- The ability to include different types of questions
- The ability to distribute the survey and manage response collection
- The ability to collect, summarize, and (securely) store response data
More advanced features can include:
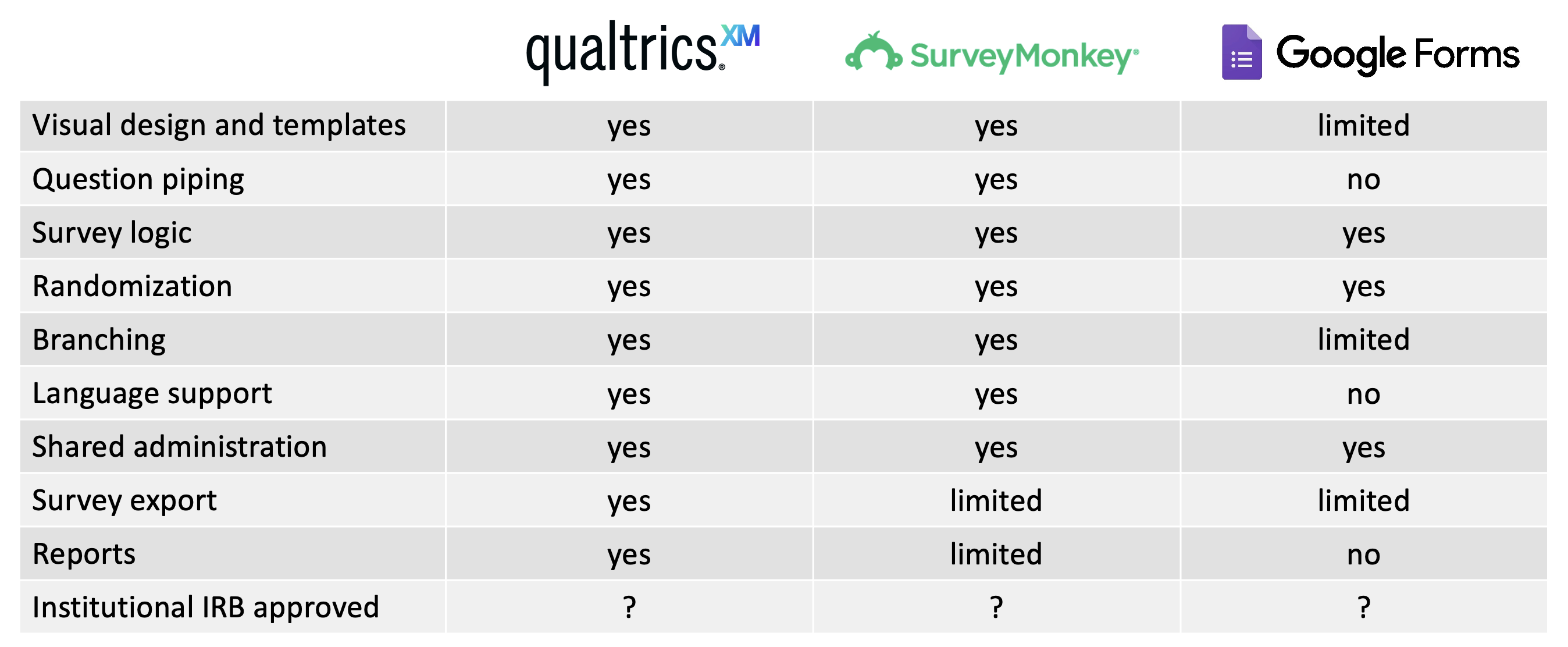
- Visual design and templates - custom design might include institutional branding or aesthetic elements. Templates allow you to save these designs and apply to other surveys
- Question piping - piping inserts answers from previous questions into upcoming questions and can personalize the survey experience for users
- Survey logic - with question logic and skip logic you can control the inclusion / exclusion of questions based on previous responses
- Randomization - the ability to randomize the presentation of questions within (blocks of) the survey
- Branching - this allows for different users to take different paths through the survey. Similar to question logic but at a bigger scale
- Language support - automated translation or multi-language presentation support
- Shared administration - enables collaboration on the survey and response analysis
- Survey export - ability to download (export) the survey instrument
- Reports - survey response visualization and reporting tools
- Institutional IRB approved - institutional IRB policy may require certain software be used for research purposes
Commonly used survey software within academic (vs market) research include Qualtrics, Survey Monkey and Google Forms. Both Qualtrics and Survey Monkey are licensed (with limited functionality available at no cost) and Google forms is free.
13.2 Building workflows using Qualtrics
In this lesson we will use the qualtRics package to reproducible access some survey results set up for this course.
13.2.1 Survey Instrument
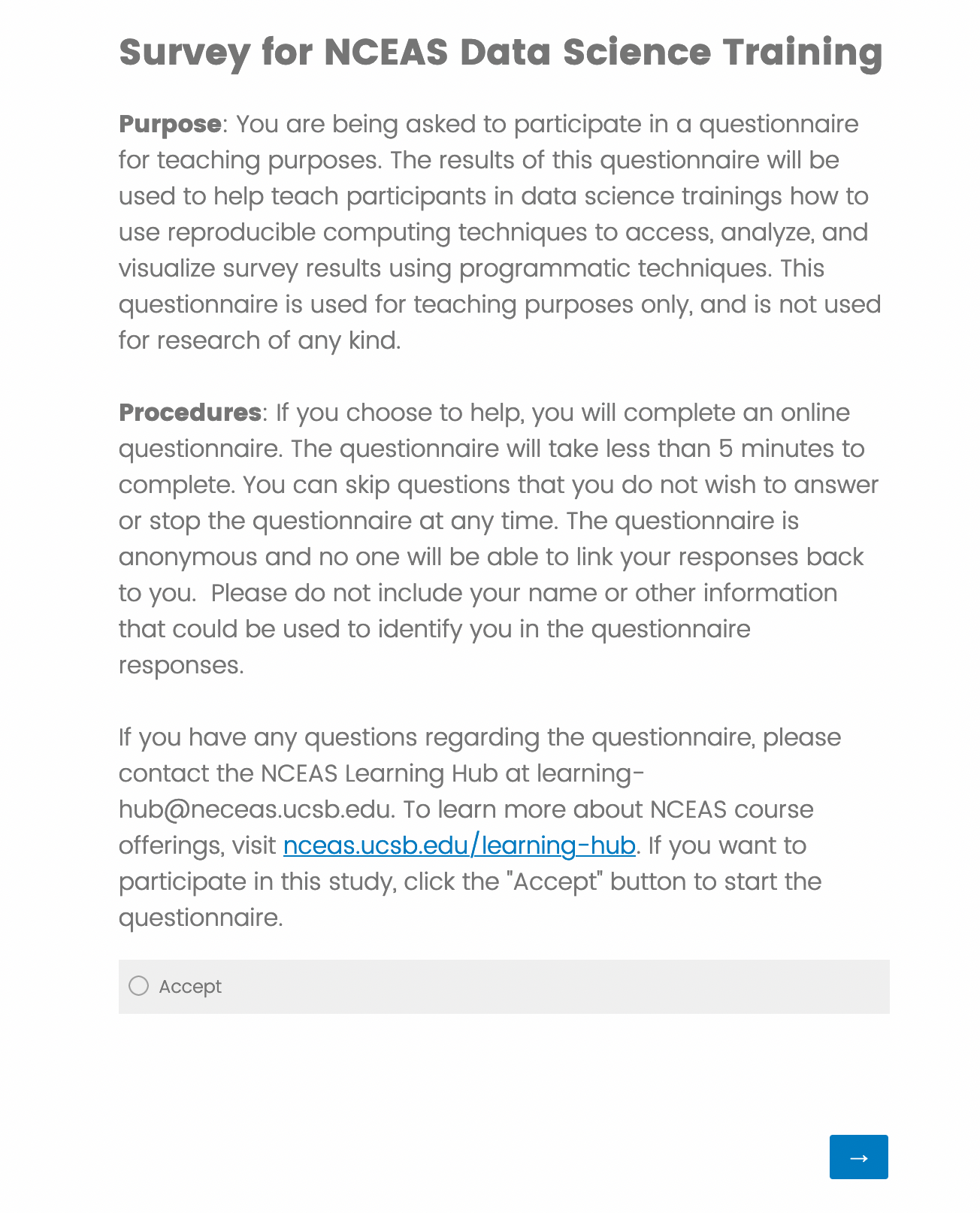
The survey is very short, only four questions. The first question is on it’s own page and is a consent question, after a couple of short paragraphs describing what the survey is, it’s purpose, how long it will take to complete, and who is conducting it. This type of information is required if the survey is governed by an IRB, and the content will depend on the type of research being conducted. In this case, this survey is not for research purposes, and thus is not governed by IRB, but we still include this information as it conforms to the Belmont Principles. The Belmont Principles identify the basic ethical principles that should underlie research involving human subjects.
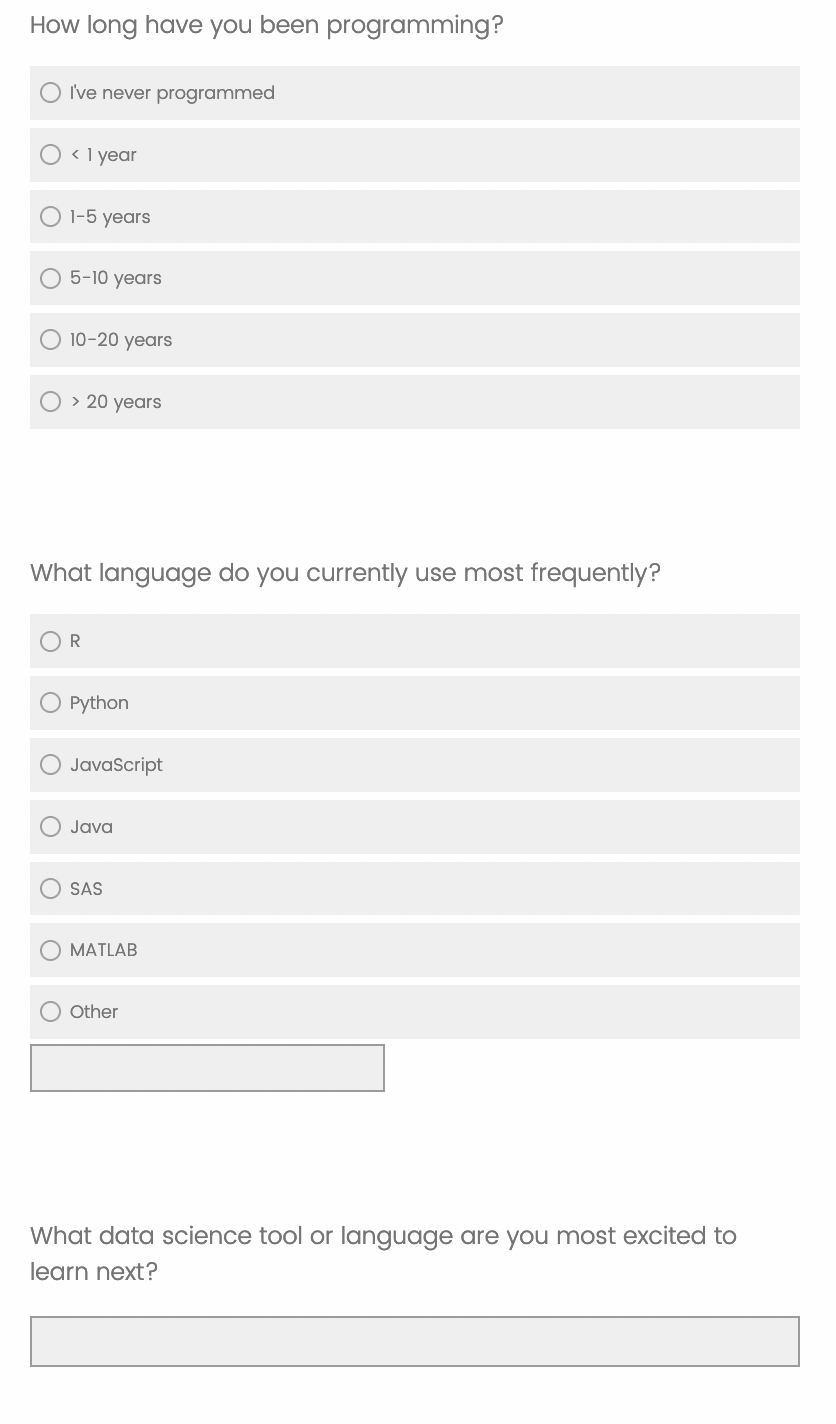
The three main questions of the survey have three types of responses: a multiple choice answer, a multiple choice answer which also includes an “other” write in option, and a free text answer. We’ll use the results of this survey, which was sent out to NCEAS staff to fill out, to learn about how to create a reproducible survey report.
13.2.2 Working with qualtiRcs
Set up
First, open a new Quarto document and add a chunk to load the libraries we’ll need for this lesson:
Next, we need to set the API credentials. This function modifies the .Renviron file to set your API key and base URL so that you can access Qualtrics programmatically.
The API key is as good as a password, so care should be taken to not share it publicly. For example, you would never want to save it in a script. The function below is the rare exception of code that should be run in the console and not saved. It works in a way that you only need to run it once, unless you are working on a new computer or your credentials changed. Note that in this book, we have not shared the actual API key, for the reasons outlined above. You should have an e-mail with the API key in it. Copy and paste it as a string to the api_key argument in the function below:
qualtrics_api_credentials(api_key = "", base_url = "ucsb.co1.qualtrics.com", install = TRUE, overwrite = T)
Aside note
The .Renviron file is a special user controlled file that can create environment variables. Every time you open Rstudio, the variables in your environment file are loaded as…environment variables! Environment variables are named values that are accessible by your R process. They will not show up in your environment pane, but you can get a list of all of them using Sys.getenv(). Many are system defaults.
To view or edit your .Renviron file, you can use usethis::edit_r_environ().
To get a list of all the surveys in your Qualtrics instance, use the all_surveys function.
surveys <- all_surveys()
kable(surveys) %>%
kable_styling()This function returns a list of surveys, in this case only one, and information about each, including an identifier and it’s name. We’ll need that identifier later, so let’s go ahead and extract it using base R from the data frame.
i <- which(surveys$name == "Survey for Data Science Training")
id <- surveys$id[i]You can retrieve a list of the questions the survey asked using the survey_questions function and the survey id.
questions <- survey_questions(id)
kable(questions) %>%
kable_styling()This returns a data.frame with one row per question with columns for question id, question name, question text, and whether the question was required. This is helpful to have as a reference for when you are looking at the full survey results.
To get the full survey results, run fetch_survey with the survey id.
survey_results <- fetch_survey(id)The survey results table has tons of information in it, not all of which will be relevant depending on your survey. The table has identifying information for the respondents (eg: ResponseID, IPaddress, RecipientEmail, RecipientFirstName, etc), much of which will be empty for this survey since it is anonymous. It also has information about the process of taking the survey, such as the StartDate, EndDate, Progress, and Duration. Finally, there are the answers to the questions asked, with columns labeled according to the qname column in the questions table (eg: Q1, Q2, Q3). Depending on the type of question, some questions might have multiple columns associated with them. We’ll have a look at this more closely in a later example.
13.2.2.1 Question 2
Let’s look at the responses to the second question in the survey, “How long have you been programming?” Remember, the first question was the consent question.
We’ll use the dplyr and tidyr tools we learned earlier to extract the information. Here are the steps:
selectthe column we want (Q1)group_byandsummarizethe values
q2 <- survey_results %>%
select(Q2) %>%
group_by(Q2) %>%
summarise(n = n())We can show these results in a table using the kable function from the knitr package:
kable(q2, col.names = c("How long have you been programming?",
"Number of responses")) %>%
kable_styling()13.2.2.2 Question 3
For question 3, we’ll use a similar workflow. For this question, however there are two columns containing survey answers. One contains the answers from the controlled vocabulary, the other contains any free text answers users entered.
To present this information, we’ll first show the results of the controlled answers as a plot. Below the plot, we’ll include a table showing all of the free text answers for the “other” option.
q3 <- survey_results %>%
select(Q3) %>%
group_by(Q3) %>%
summarise(n = n())ggplot(data = q3,
mapping = aes(x = Q3, y = n)) +
geom_col() +
labs(x = "What language do you currently use most frequently?", y = "Number of reponses") +
theme_minimal()Now we’ll extract the free text responses:
q3_text <- survey_results %>%
select(Q3_7_TEXT) %>%
drop_na()
kable(q3_text, col.names = c("Other responses to 'What language do you currently use mose frequently?'")) %>%
kable_styling()13.2.2.3 Question 4
The last question is just a free text question, so we can just display the results as is.
q4 <- survey_results %>%
select(Q4) %>%
rename(`What data science tool or language are you most excited to learn next?` = Q4) %>%
drop_na()
kable(q4, col.names = "What data science tool or language are you most excited to learn next?") %>%
kable_styling()13.3 Other survey tools
13.3.1 Google forms
Google forms can be a great way to set up surveys, and it is very easy to interact with the results using R. The benefits of using google forms are a simple interface and easy sharing between collaborators, especially when writing the survey instrument.
The downside is that google forms has far fewer features than Qualtrics in terms of survey flow and appearance.
To show how we can link R into our survey workflows, I’ve set up a simple example survey here.
I’ve set up the results so that they are in a new spreadsheet here:. To access them, we will use the googlesheets4 package.
First, open up a new Quarto doc and load the googlesheets4 library:
library(googlesheets4)Next, we can read the sheet in using the same URL that you would use to share the sheet with someone else. Right now, this sheet is public
responses <- read_sheet("https://docs.google.com/spreadsheets/d/1CSG__ejXQNZdwXc1QK8dKouxphP520bjUOnZ5SzOVP8/edit?usp=sharing")✔ Reading from "Example Survey Form (Responses)".✔ Range 'Form Responses 1'.The first time you run this, you should get a popup window in your web browser asking you to confirm that you want to provide access to your google sheets via the tidyverse (googlesheets) package.
My dialog box looked like this:
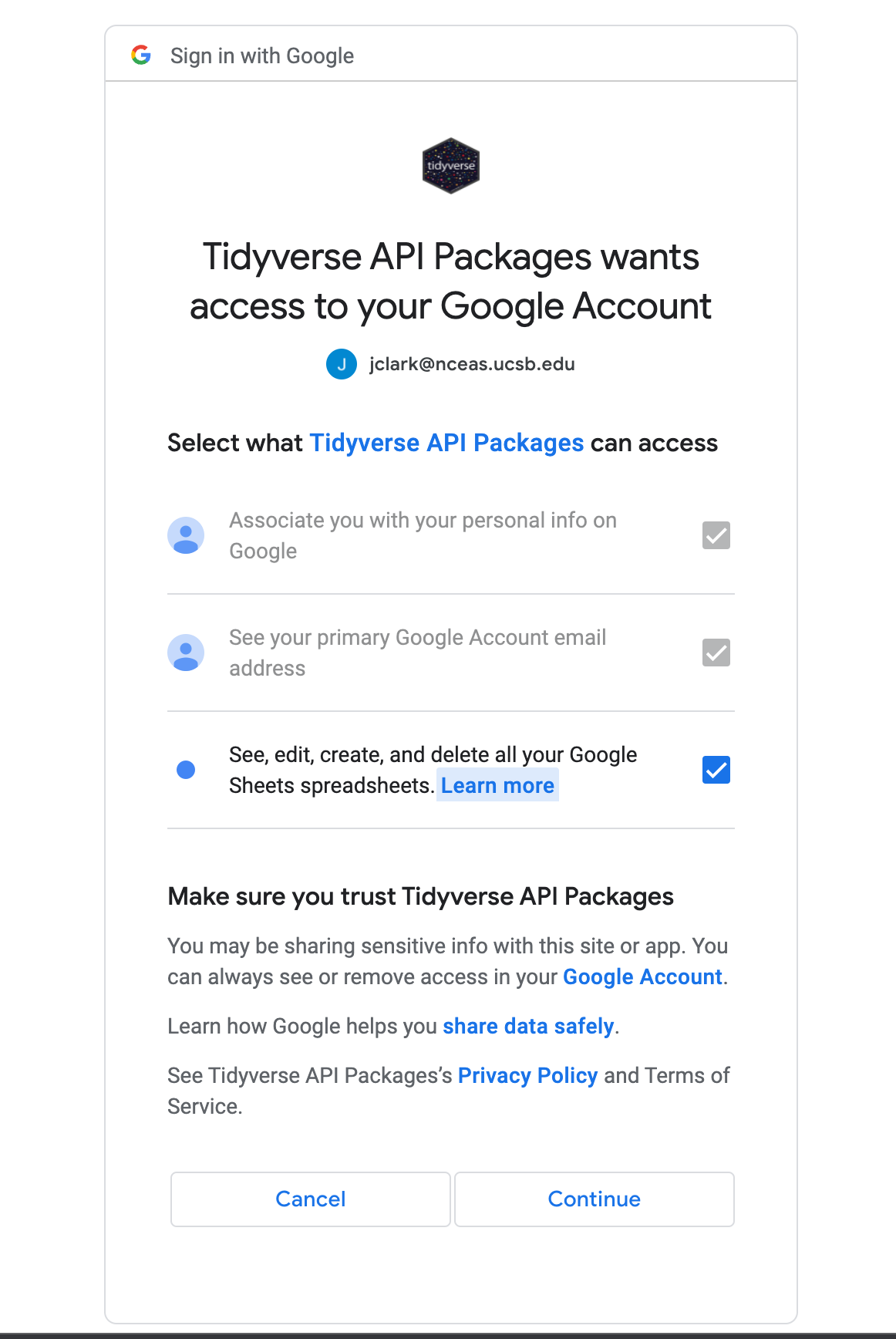
Make sure you click the third check box enabling the Tidyverse API to see, edit, create, and delete your sheets. Note that you will have to tell it to do any of these actions via the R code you write.
When you come back to your R environment, you should have a data frame containing the data in your sheet! Let’s take a quick look at the structure of that sheet.
dplyr::glimpse(responses)Rows: 10
Columns: 5
$ Timestamp <dttm> 2022-04-15 13:…
$ `To what degree did the event meet your expectations?` <chr> "Met expectatio…
$ `To what degree did your knowledge improve?` <chr> "Increase", "Si…
$ `What did you like most about the event?` <chr> "the cool instr…
$ `What might you change about the event?` <chr> "more snacks", …So, now that we have the data in a standard R data.frame, we can easily summarize it and plot results. By default, the column names in the sheet are the long fully descriptive questions that were asked, which can be hard to type. We can save those questions into a vector for later reference, like when we want to use the question text for plot titles.
questions <- colnames(responses)[2:5]
dplyr::glimpse(questions) chr [1:4] "To what degree did the event meet your expectations?" ...We can make the responses data frame more compact by renaming the columns of the vector with short numbered names of the form Q1. Note that, by using a sequence, this should work for sheets from just a few columns to many hundreds of columns, and provides a consistent question naming convention.
names(questions) <- paste0("Q", seq(1:4))
questions Q1
"To what degree did the event meet your expectations?"
Q2
"To what degree did your knowledge improve?"
Q3
"What did you like most about the event?"
Q4
"What might you change about the event?" colnames(responses) <- c("Timestamp", names(questions))
dplyr::glimpse(responses)Rows: 10
Columns: 5
$ Timestamp <dttm> 2022-04-15 13:48:58, 2022-04-15 13:49:43, 2022-04-15 13:50:…
$ Q1 <chr> "Met expectations", "Above expectations", "Above expectation…
$ Q2 <chr> "Increase", "Significant increase", "Significant increase", …
$ Q3 <chr> "the cool instructors", "R is rad!", "everything", "the pizz…
$ Q4 <chr> "more snacks", "no pineapple pizza!", "nothing", "needs more…Now that we’ve renamed our columns, let’s summarize the responses for the first question. We can use the same pattern that we usually do to split the data from Q1 into groups, then summarize it by counting the number of records in each group, and then merge the count of each group back together into a summarized data frame. We can then plot the Q1 results using ggplot:
q1 <- responses %>%
dplyr::select(Q1) %>%
dplyr::group_by(Q1) %>%
dplyr::summarise(n = dplyr::n())
ggplot2::ggplot(data = q1, mapping = aes(x = Q1, y = n)) +
geom_col() +
labs(x = questions[1],
y = "Number of reponses",
title = "To what degree did the course meet expectations?") +
theme_minimal()Bypassing authentication for public sheets
If you don’t want to go through a little interactive dialog every time you read in a sheet, and your sheet is public, you can run the function gs4_deauth() to access the sheet as a public user. This is helpful for cases when you want to run your code non-interactively. This is actually how I set it up for this book to build!
13.3.2 Survey Monkey
Similar to Qualtrics and qualtRics, there is an open source R package for working with data in Survey Monkey: Rmonkey. However, the last updates were made 5 years ago, an eternity in the software world, so it may or may not still function as intended.
There are also commercial options available. For example, cdata have a driver and R package that enable access to an analysis of Survey Monkey data through R.