1 Session 1: Time Series and Forecasting
1.1 Learning Objectives
These lessons are the equivalent of a city bus tour. They are a high level tour of some useful functions.
There are plenty of more detailed lessons on the internet. I would recommend starting with the “Forecasting Principles and Practice v2” by Rob Hyndman who wrote the forecast package.
Today we will take a tour with the predict function in R, as well as some advanced time series statistics that are provided by the forecast package.
In this session you will learn how to
- Simulate data and test if your model is working as expected
- Use linear regression to fit and predict time series
- Visualize data
- Decompose a time series into seasonal, trend, and error
a note on the forecast package Hydnman and others are creating the successor to the forecast package called ‘feasts.’ The next version of the text uses this package https://otexts.com/fpp3/.
1.2 Linear regression, with time as a predictor
Both the simulation of data and the fitting of the model here is a general approach. It is demonstrated with a simple regression model of increasing \(Y\) as a funciton of time. But simulating data can be very useful in understanding your data, your model, and the about statistics in general.
First, lets define our data model.
We want to fit. simulate a time series of one observations on each of ten subsequent dates:
Our data model is effectively
\[ Y_{\textrm{linear}}=1+2t +\epsilon\\ \epsilon\sim N(0,1) \] Where y is the mass of your favorite organism. They are born on day 0 with 1 g and growth on average is 2 grams per day.
library(forecast)
library(dplyr)
library(lubridate)
library(broom)
set.seed(103)
days <- 0:9
mass <- vector(length = 10)
for(t in seq_along(days)){
mass[t] <- 1 + 2 * days[t] + rnorm(1, 0, 1)
}
linear_data <- data.frame(day = days, mass = mass)
plot(mass~day,
data = linear_data,
ylab = 'mass (g)',
ylim = c(1, 20),
xlim = c(0, 15))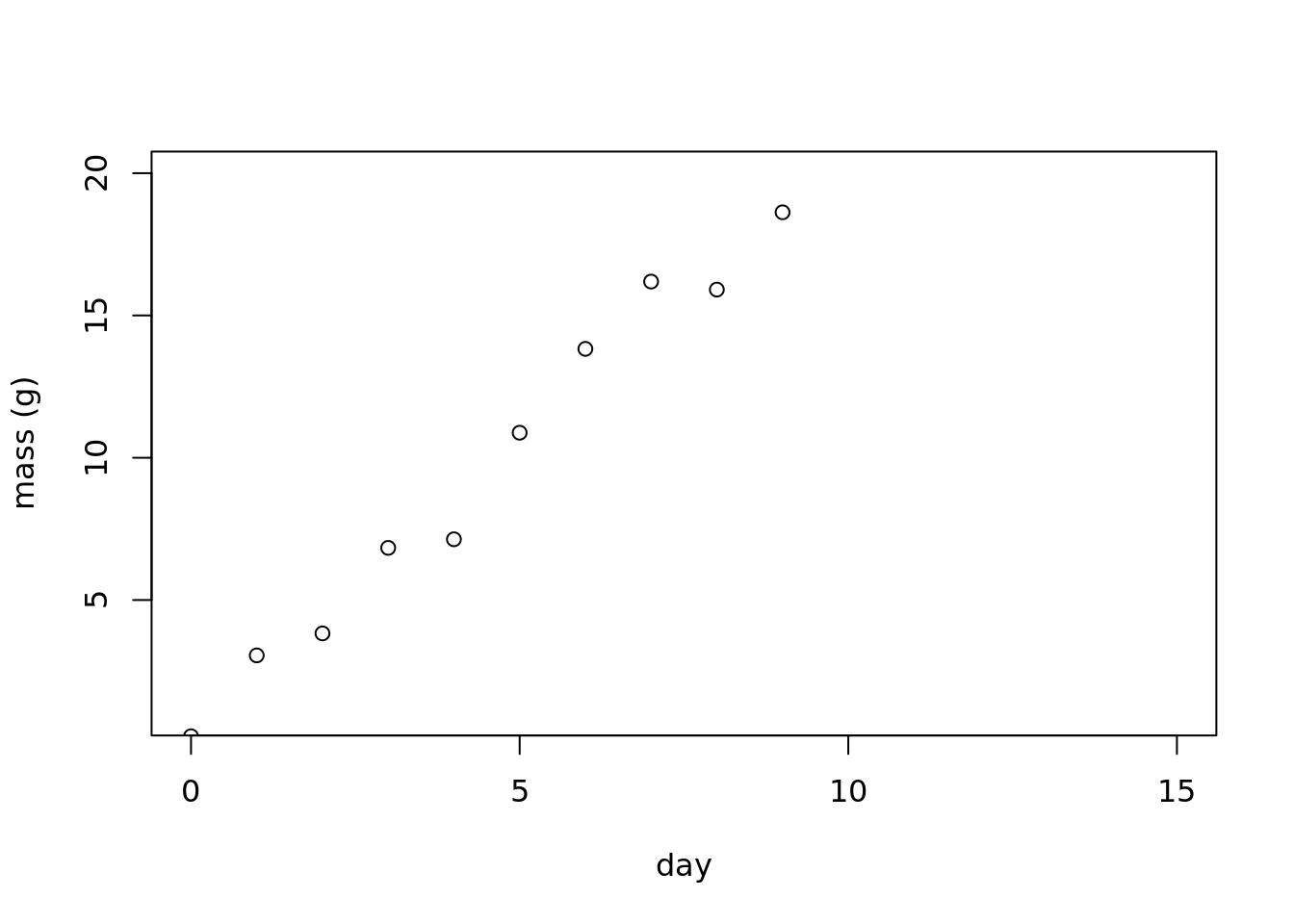
Now, we can fit a linear regression, and estimate the parameters. Did the model find the ‘right’ values?
mod_linear <- lm(mass ~ 1 + days, data = linear_data)
tidy(mod_linear)## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.316 0.560 0.565 0.588
## 2 days 2.07 0.105 19.8 0.0000000447Did we recover the correct parameters from the simulated data?
Don’t forget to check assumptions! plot(lm)
mod_linear##
## Call:
## lm(formula = mass ~ 1 + days, data = linear_data)
##
## Coefficients:
## (Intercept) days
## 0.316 2.074## you can look at model statistics
summary(mod_linear)##
## Call:
## lm(formula = mass ~ 1 + days, data = linear_data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.4773 -0.5670 0.0455 0.5720 1.3558
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.316 0.560 0.56 0.59
## days 2.074 0.105 19.77 4.5e-08 ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.953 on 8 degrees of freedom
## Multiple R-squared: 0.98, Adjusted R-squared: 0.977
## F-statistic: 391 on 1 and 8 DF, p-value: 4.47e-08## don't forget to check assumptions, etc
## this is helpful even when you simulate and you know
## that the data generating process is valid; get an idea of what is 'okay'
# plot(mod_linear)1.3 Time series ‘feature extraction’
We’ve already extracted features from our time series. What are ‘features?’ These are properties underlying the data. In this case, the information in our time series has been condensed into a slope and intercept.
There are a lot of other mathematical functions that can be fit to your data, and properties of these functions that can be extracted, and used in subsequent analyses.
Bolker (2007) provides a ‘bestiary of functions’ in chapter 3 of his book “Ecological Models and Data in R”. It provides some biological meanings and useful contexts for a variety of linear and non-linear, continuous and discontinuous functions.
This is a common and very useful way of converting a time series into features.
For an example of Bayesian logistic regression using JAGS, see the work done by Jessica Guo and me: https://github.com/genophenoenvo/JAGS-logistic-growth.
Dietze’s Ecological forecasting course shows how to simulate a logistic growth curve using Monte Carlo methods. https://github.com/EcoForecast/EF_Activities/blob/master/Exercise_02_Logistic.Rmd
There are a huge number of other methods for ‘dimensionality reduction.’ Principal components analysis is an important one. Another is taking a full resolution image and reducing the resolution to a few pixels square, and everything in between. In the ‘machine learning’ world a wide range of methods are used in a process that they call ‘encoding’ .
1.3.1 The ‘predict’ function: forecasting with a fitted regression model
The predict function in R has a variety of uses. Last week we learned how to use it to impute missing data values. This week, we will learn how to use it to predict the next time points in our time series.
First step, lets predict what is the expected value on the subsequent few days. This is using the fitted slope and intercept to plot a single value on the regression line for each day.
We will plot the data in black, the new points in red, and the regression line.
newdays <- 11:15
newdat <- data.frame(days = newdays)
preds <- predict(mod_linear,
newdata = newdat)
plot(mass ~ day,
data = linear_data,
ylab = 'mass (g)',
ylim = c(1, 30),
xlim = c(0, 15)) +
points(newdays, preds, col = 'red') +
abline(coef(mod_linear)) +
abline(confint(mod_linear)[,1], lty = 2) +
abline(confint(mod_linear)[,2], lty = 2)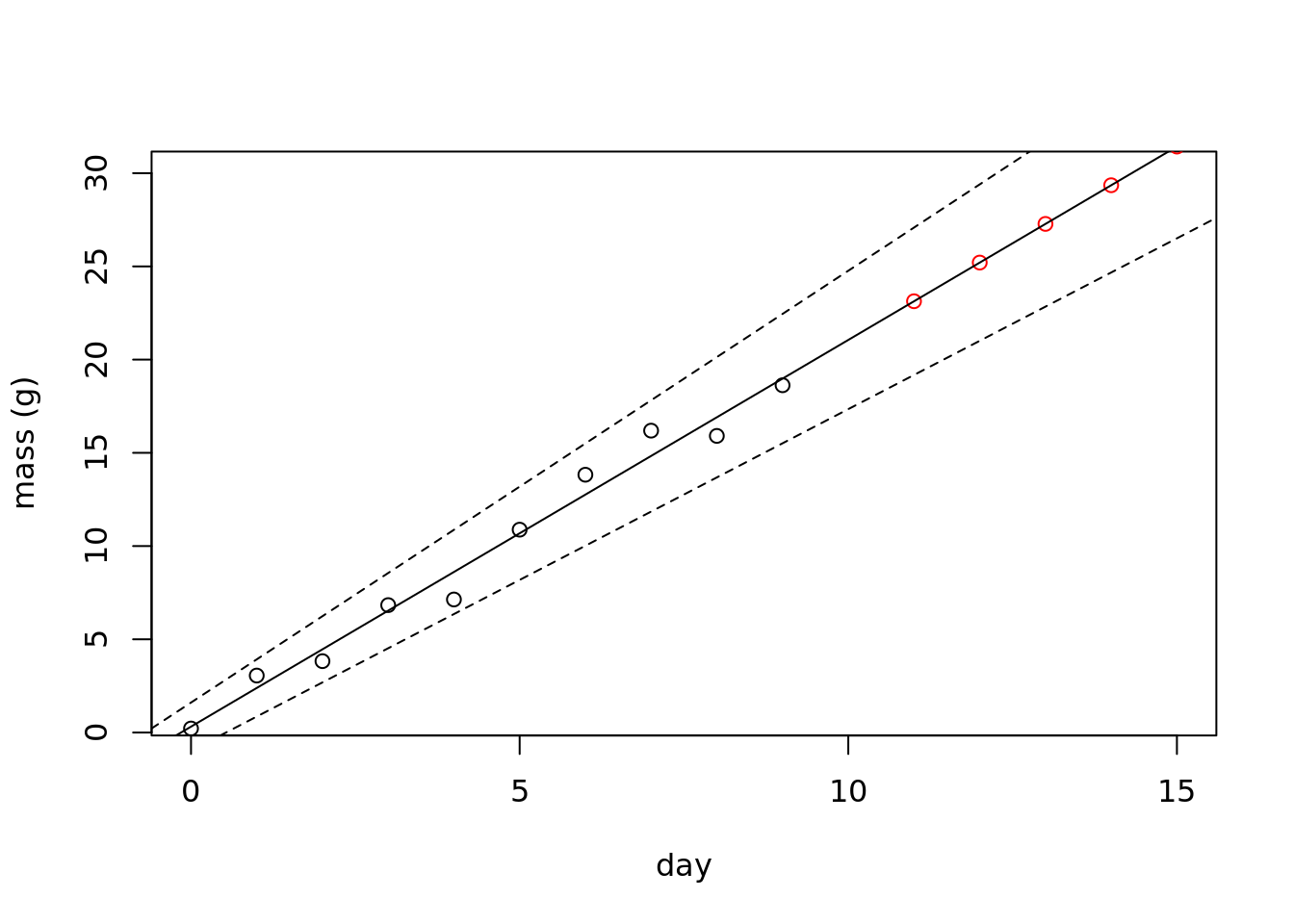
## integer(0)Now, we have predicted the next five days of growth!
1.4 Time Series objects in R
R has a specific type of time series ‘object.’ that is analogous to a ‘data.frame,’ but special. It is called a time series object - ‘ts’ (or ‘mts’ for a multivariate time series). See ?ts
Lets create time series objects so that we can use some of the basic functions for time series analysis.
How to make a time series object.
Last week when we learned about the imputeTS package, we skipped over what we actually did to make a time series object.
We set the start and end by year and index, and then either a time step ‘deltat’ or frequency.
Values of frequency (per year): - daily data: 365 - monthly: 12 - hourly: 365*24 - etc
Lets make some sample monthly time series for three cases
- for white noise: \(Y=\epsilon\)
- with autocorrelation with a 1 month lag \(Y_t=\frac{Y_{t-1}+Y_{t}}{2}\)
- with autocorrelation and a trend \(Y_t=\frac{Y_{t-1}+Y_{t}}{2} + \frac{t}{48}+\epsilon\)
- with seasonal patterns \(Y_t=\sin(\frac{2\pi t}{12})+\epsilon\)
- with seasonal patterns and a trend \(Y_t=\sin(\frac{2\pi t}{12})+\frac{t}{48} + \epsilon\)
Where \(t\) is the time step (in units of months). The second equation takes the average of the last time step and the current one (a moving window of size 2). The third equation adds a trend - every month the value increases by 1/120.
set.seed(210)
months <- 1:240
noise <- rnorm(length(months))
lag <- vector()
for(t in 1:length(months)){
if(t == 1){
lag[t] <- rnorm(1)
} else {
lag[t] <- (lag[t-1] + noise[t]) / 2
}
}
lag_trend <- lag + months / 48
seasonal <- 2*sin(2*pi*months/12) + noise
seasonal_trend <- seasonal + months / 48 Now lets create the multivariate time series object:
all <- ts(data = data.frame(noise, lag, lag_trend, seasonal, seasonal_trend),
frequency = 12)
plot(all)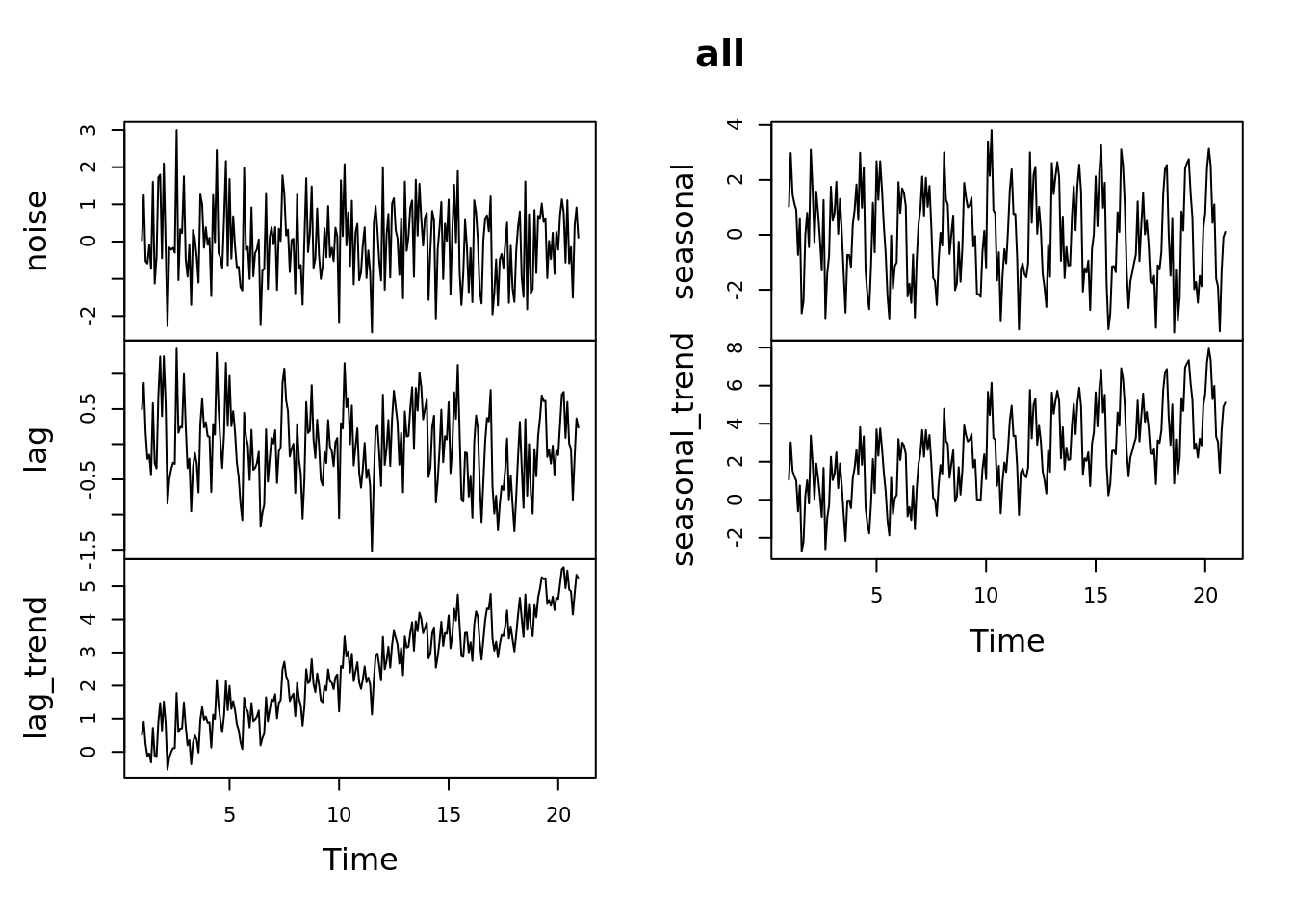
tsdisplay(all)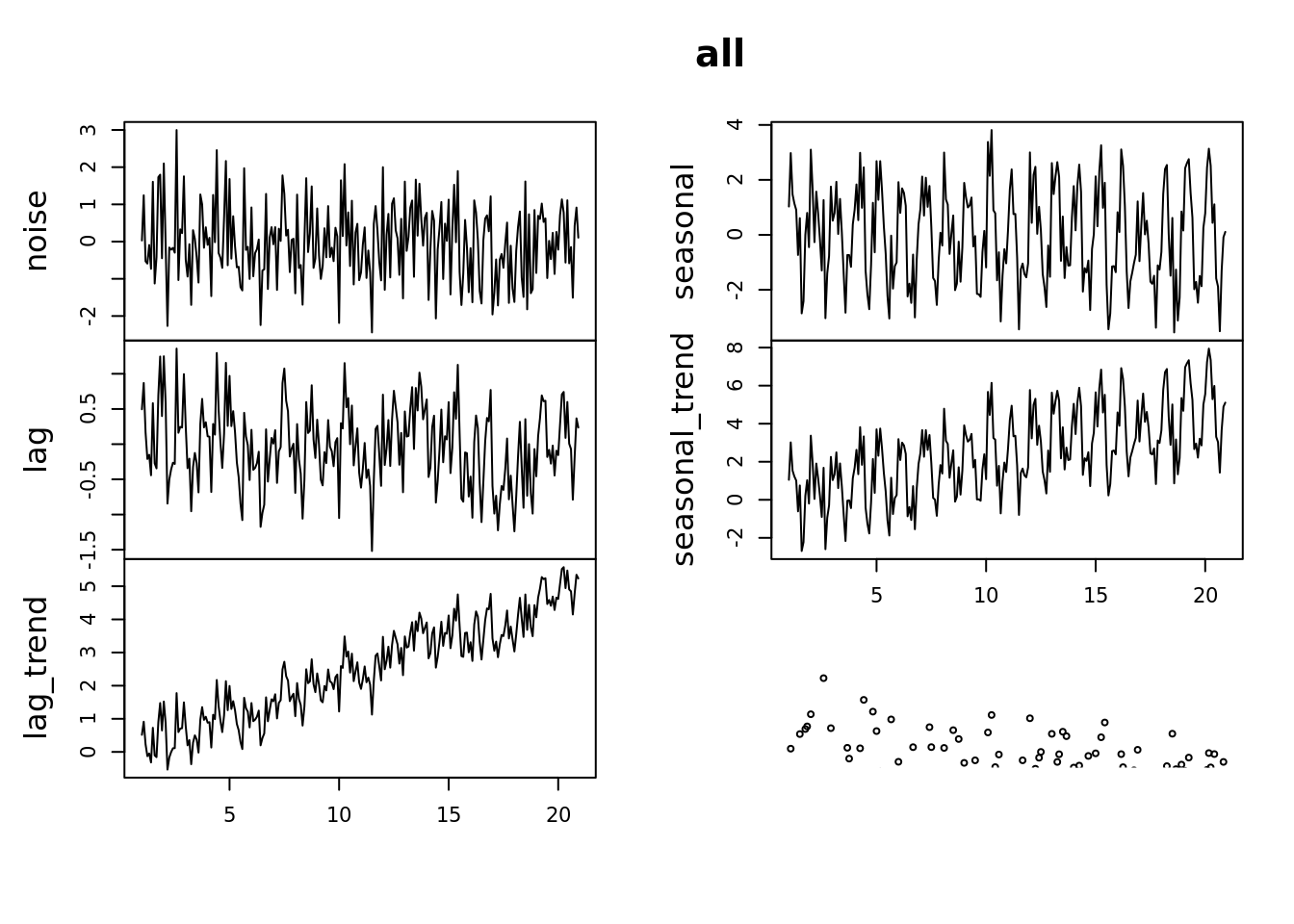
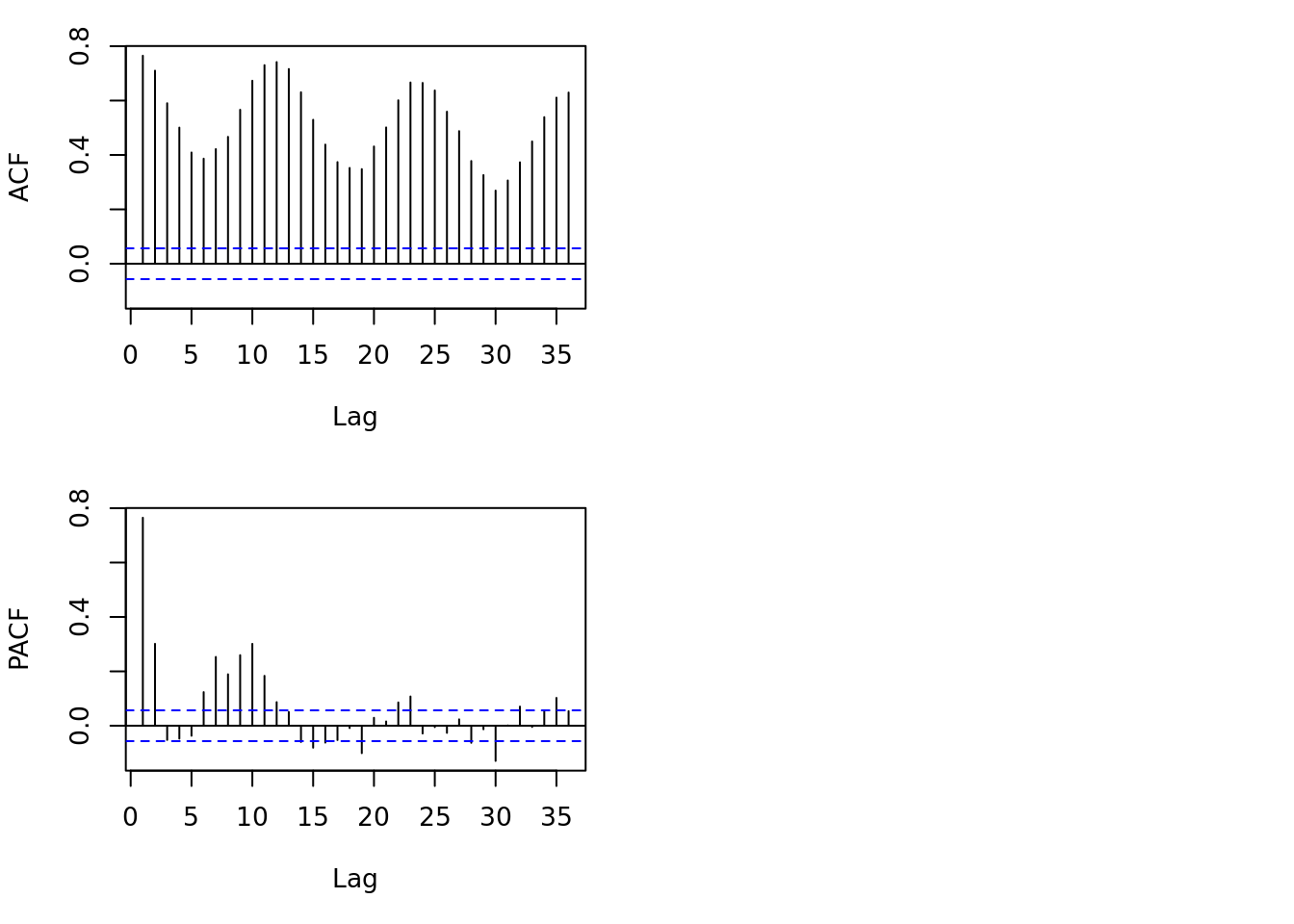
Lets look at some basic statistics: which of these have a lag?
This plot will show the correlation between \(Y_t\) and \(Y_{t-\textrm{lag}}\)
lag.plot(all, set.lags = c(1, 3, 6, 9))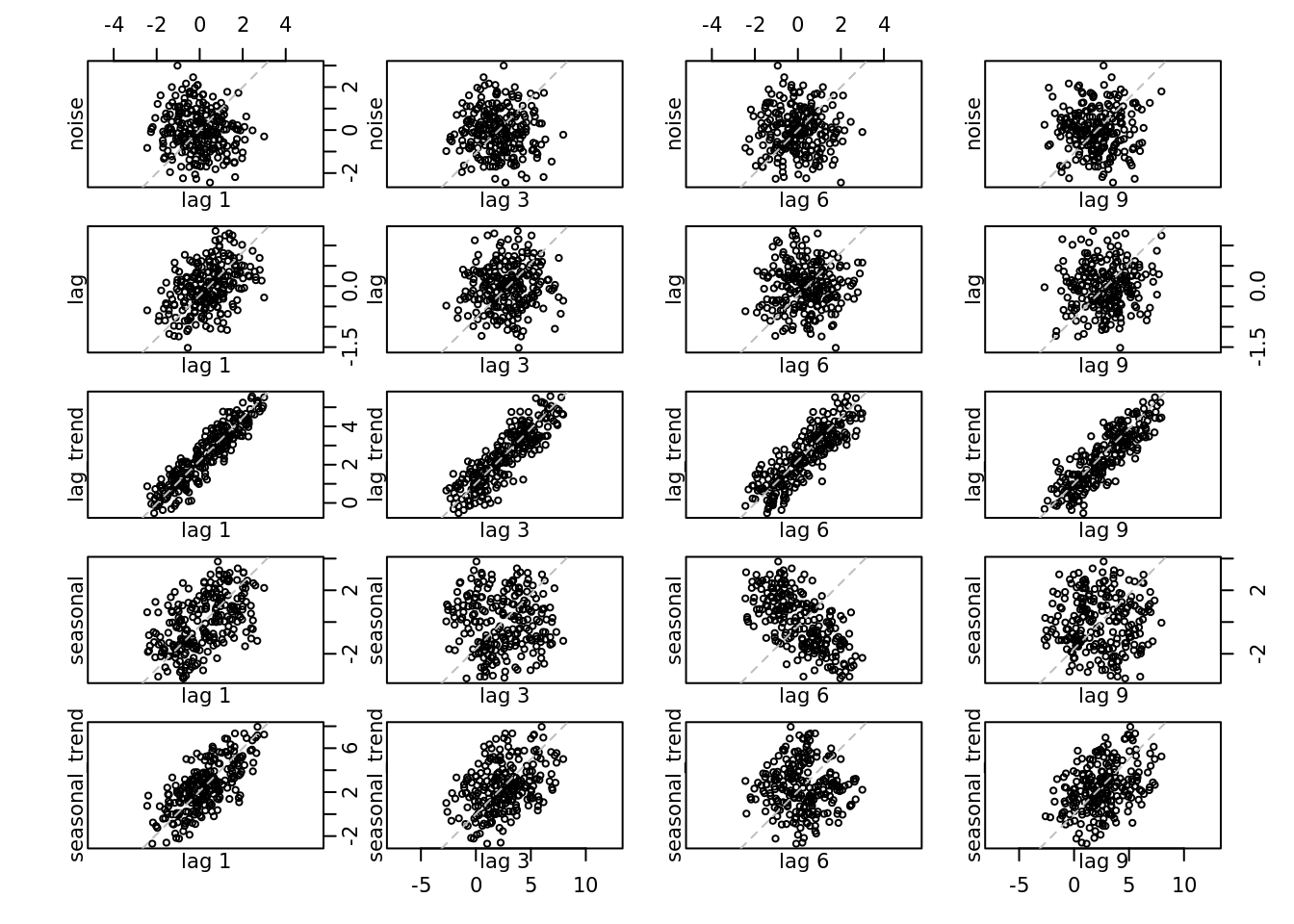
1.4.1 Autocorrelation plots
acf(all[,'noise'], xlab = 'Lag (years)')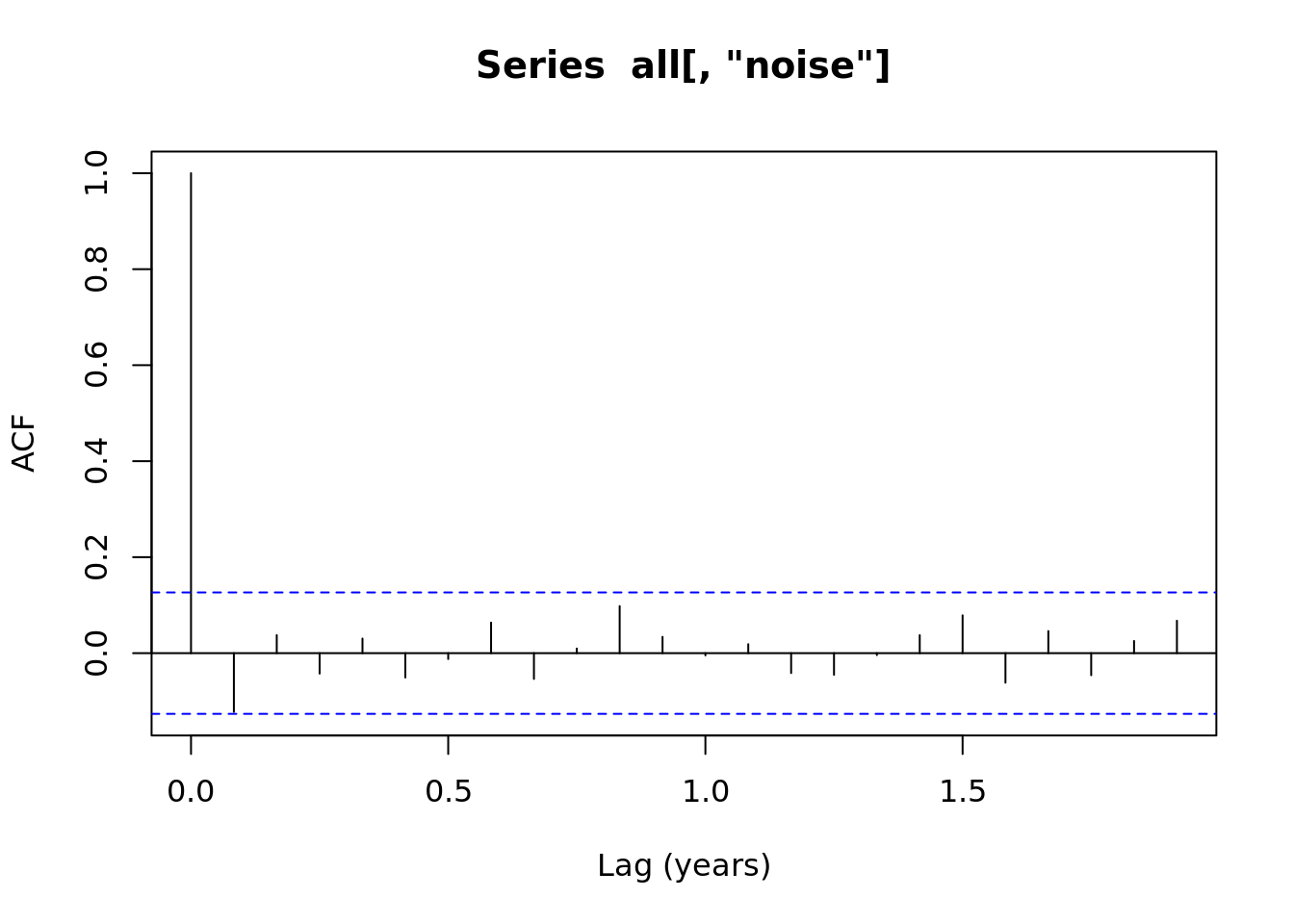
acf(all[,'lag'], xlab = 'Lag (years)')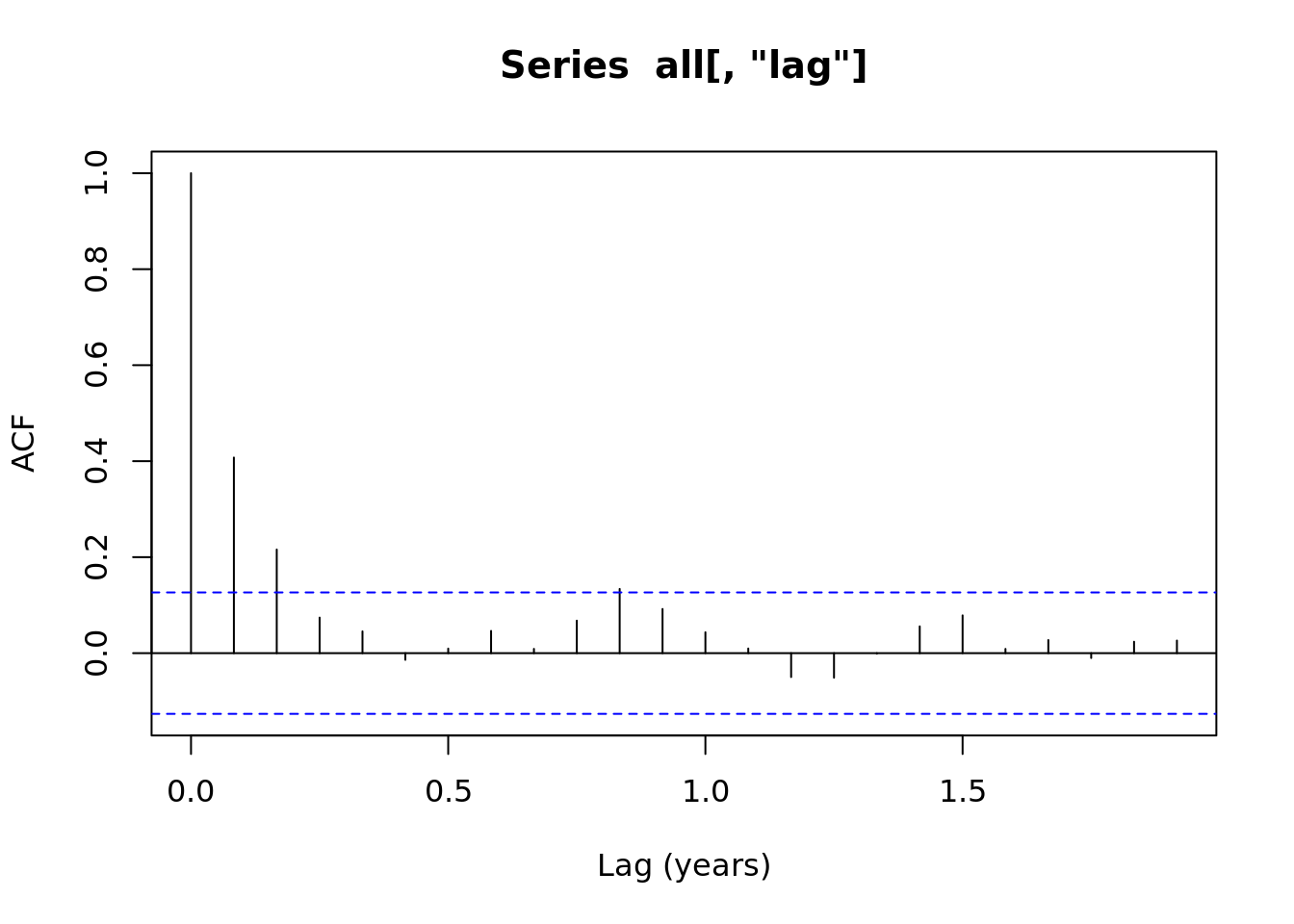
acf(all[,'seasonal'], xlab = 'Lag (years)')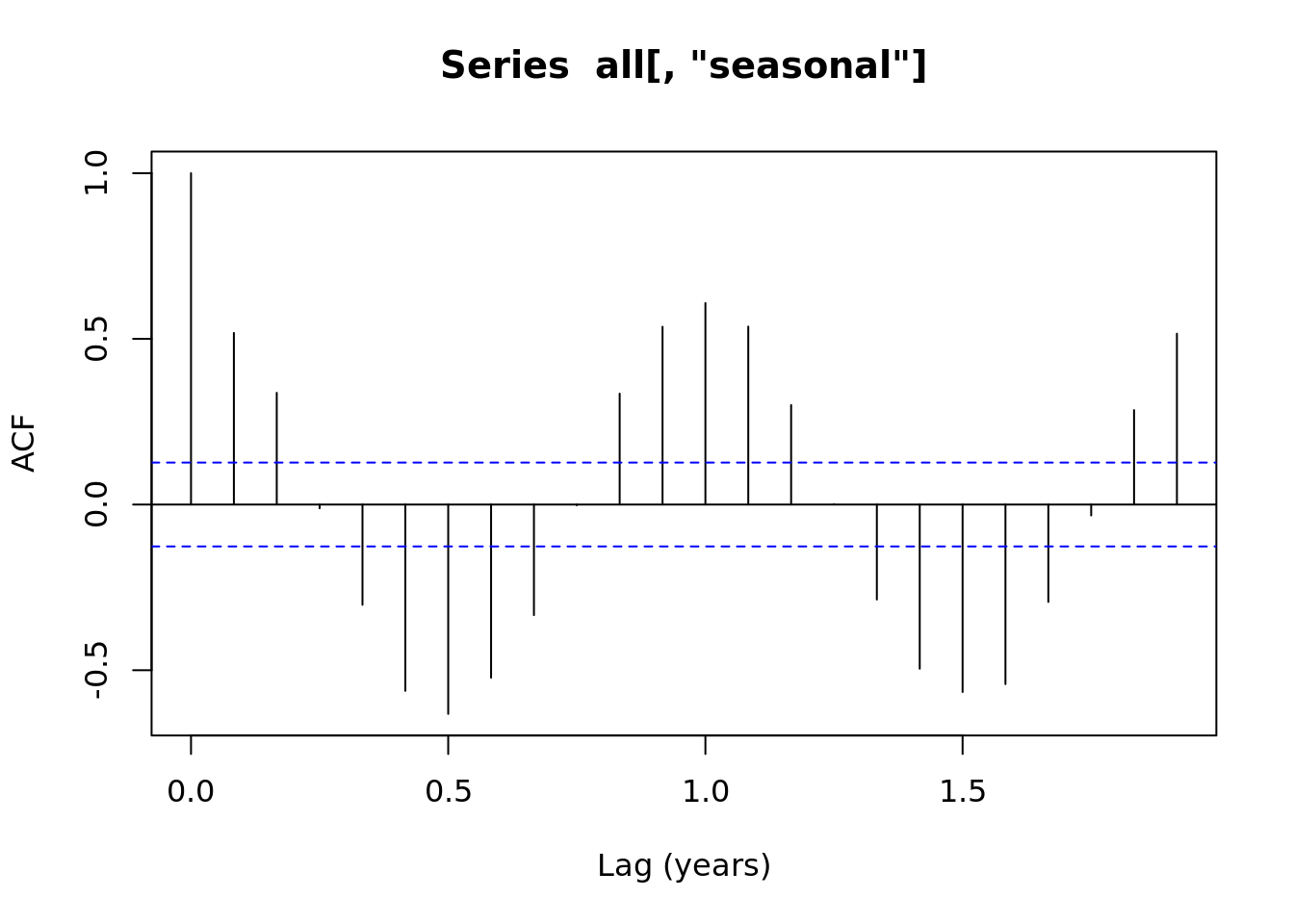 ### Time Series Decomposition
### Time Series Decomposition
We want to look at a time series in terms of its components.
R has a number of handy functions for basic time series analysis. Lets take a look.
Lets look at some of the basic components of a time series
- seasonal patterns
- trend
- residuals
dec <- decompose(all[,'seasonal_trend'])
plot(dec)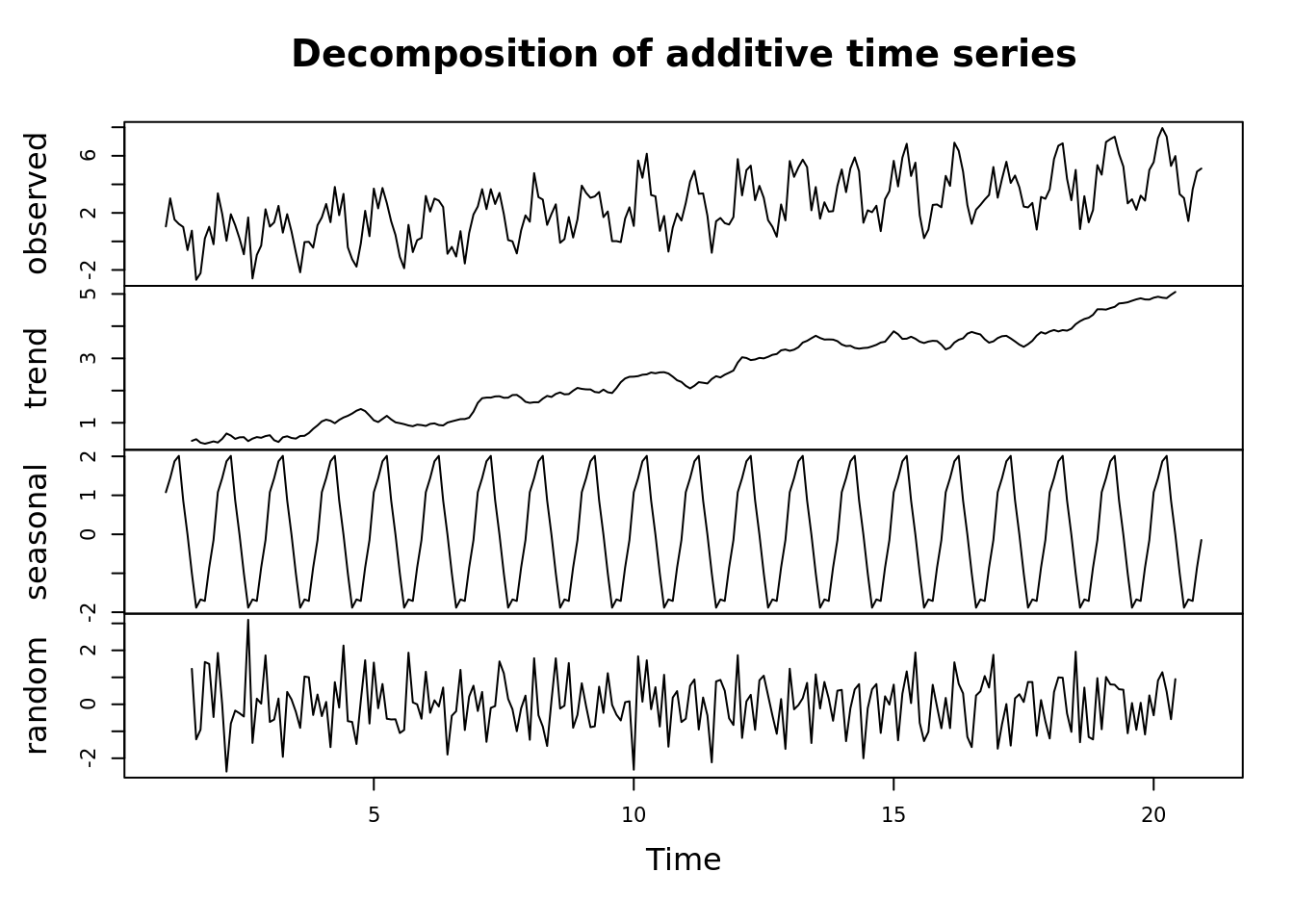
dec_df <- data.frame(trend = dec$trend, month = months)
dec_df <- dec_df[!is.na(dec_df),]
tidy(lm(trend ~ month, data = dec_df))## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.101 0.0345 2.92 3.85e- 3
## 2 month 0.0197 0.000251 78.5 6.10e-1661.4.2 Seasonal Trend with Loess smoothing (STL) decomposition
The seasonal component of the decomposed time series is very regular. The acf() function creates a seasonal component using the means. Lets look at a more sophisticated model - the seasonal trend with local (Loess) smoothing
If we are interested in a longer term trend, lets use the Seasonal trend w/ local smoothing Loess (STL) to smooth over a few years.
- trend window > seasonal window
- has some rule of thumbs for estimating the parameters
seasonal_stl <- stl(all[,'seasonal_trend'], s.window = 6)
plot(seasonal_stl)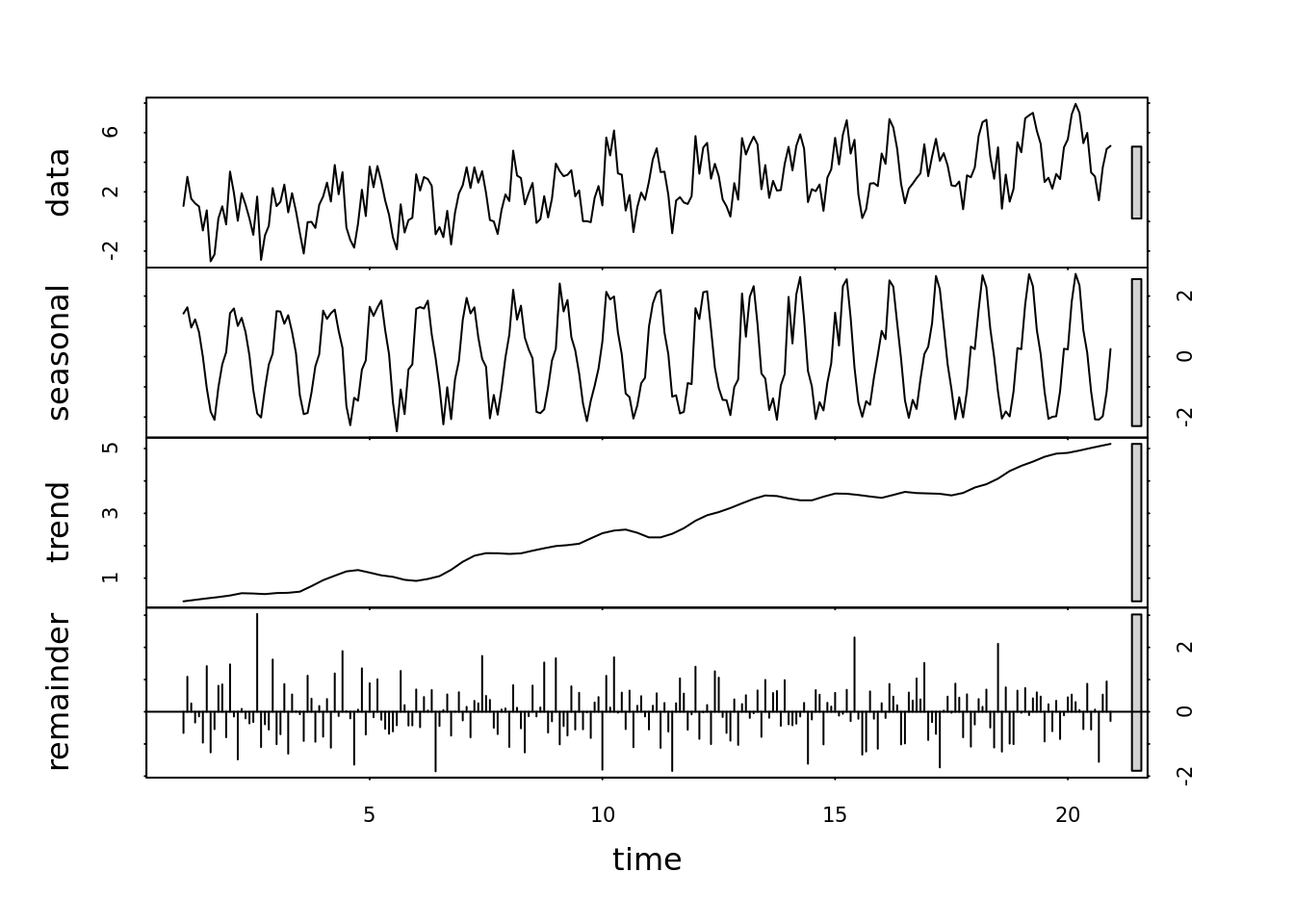
## note how you can access each component of the decomposed time series
## plot(seasonal_stl$time.series[,c('trend', 'seasonal', 'remainder')])1.4.3 Now we can analyze the trend
tmp <- data.frame(month = months, trend = seasonal_stl$time.series[,'trend'])
#plot(tmp$month, tmp$trend)
fit <- lm(trend ~ month, data = tmp)
coef(fit)## (Intercept) month
## 0.1014 0.0198tidy(fit)## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.101 0.0277 3.66 3.14e- 4
## 2 month 0.0198 0.000199 99.4 8.74e-196z <- rnorm(10000, 0.019, 0.0002208)What does that coefficient ‘month’ mean?
1.4.4 Some Time Series Model Acronyms
ARIMA Models
You will often see time series models specified as ARIMA(p,d,q)
AR: AutoRegressive time series I: Integrated MA: Moving Average smoothing
- p number of lags
- d degree of differencing
- q size of moving average window
The forecast::auto.arima function automatically fits these parameters. See https://otexts.com/fpp2/arima-r.html for an explanation of how this function works.
STL Seasonal Seasonal Decomposition of Time Series by Loess. Extracts trend, seasonal, and locally smoothed moving average (described above).
ETS Exponential smoothing state space model.
1.4.5 State Space Models
- Latent variable - this is the process of interest. Not directly measured, but measured with an ‘observation model’ a.k.a. whatever is used to actually measure - often boils down to changes in an electric current that capture a property of interest.
It could be a model of a pendulum or similar dynamical system.
https://upload.wikimedia.org/wikipedia/commons/2/24/Oscillating_pendulum.gif
{kind=link}
Ruryk, CC BY-SA 3.0, via Wikimedia Commons
{kind=link}
Imagine you are interested in ‘growth rate.’ Then you measure the size (how? mass? length?…) of your tree, fish, or other organism of interest. Yesterday, today, and tomorrow. You can then estimate the growth rate by these differences. In turn, the growth rate could also be controlled by time, temperature, resource availability. These might each have its own latent and observed variables.
- State-space models
State space models are models of how the state of a system changes over time.
A state-space They provide a series of equations that represent how a system evolves in time. These models are widely used in the study of complex systems.
For example, a model of population dynamics that accounts for growth, reproduction, and death, geophysical at a particular place. Rocket scientists and robotics engineers, car manufacturers and video game designers all use complex models of a system that function in this way.
Such a model can take parameters for equations that control the the dynamics of the system (e.g ‘growth rate’). you know the state of a system, and how the system changes in time, you can use a state-space framework. once it represents the current state, it can be represent the state of a system. Conceptually, they are a way of modeling time series when you have a model of the ‘process’ or mechanism that moves the system state from \(t\) to \(t+1\).
The ‘state’ of the system may be partially unobserved. But we can infer these states based on observations.
The concept of a ‘data generating process’ is an important concept when modeling, and when synthesizing data from many different locations. A ‘data generating process’ includes both the system being studied and the tools used to observe. It is common to hear people refer to data as if it is the truth. But data can only represent an incomplete view of the system itself. In the end both data and models are representations of a system.
Consider satellite imagery, radiative transfer models.
1.5 Ecological Forecasting
Like time series, forecasting is a very large area of research.
Ecological forecasting is an emerging discipline, and it covers both basic research and the application of ecological understanding to applications. Forecasts can help provide insights into the future state of a system as well as provide guidance on management scenarios.
That is exactly what it sounds like you need to do!
Some examples of ecological forecasting problems:
Where is the hurricane going to end up?
How much carbon can the land store?
How will flooding affect delta planton and fish populations?
Predict the potential yield of different crops under future climates

Predict forest green up and senescence
Key references include Clark et al 2001 and Dietze et al 2018 below. The Ecological Forecasting Initiative (EFI, ecoforecast.org) is a Research Coordination Network that you can join to learn and contribute to the development of this field.
1.5.1 Forecasting Challenges
There are a variety of forecasting challenges. These can be found on sites like Kaggle. Lets look at a few
- EFI NEON forecasting Challenge
- phenology, net ecosystem exchange, beetle abundance, water temperature and dissolved oxygen
- Kaggle: Predict end of season Sorghum biomass from photograps
- HiveMind / Agrimetrics UK Wheat yield forecast market Yield 21
A note on challenges. Framing a problem as a challenge is a great way to engage the machine learning world. And these challenges provide a way to engage other communities, and lower the barrier to entry and more level playing field than many scientific pursuits. For challenges like those on Kaggle and the ones run by EFI, the best model wins.
1.5.2 The forecasting toolbox
As we discussed last week, there are some simple or ‘naiive’ ways to forecast. These approaches are useful, sometimes because they perform well and other times because they provide a reasonable null hypothesis. Some use the same methods that we used to interpolate.
The forecast package has a lot of handy functions for time series data. Lets start with the moving average.
ts_fit <- tslm(all[,'seasonal_trend'] ~ trend + season, data = all)
summary(ts_fit)##
## Call:
## tslm(formula = all[, "seasonal_trend"] ~ trend + season, data = all)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.3808 -0.7578 0.0051 0.6621 3.0736
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.174807 0.254138 4.62 6.4e-06 ***
## trend 0.019863 0.000956 20.78 < 2e-16 ***
## season2 0.439280 0.324043 1.36 0.17657
## season3 0.775615 0.324047 2.39 0.01750 *
## season4 0.887002 0.324054 2.74 0.00669 **
## season5 -0.212659 0.324064 -0.66 0.51234
## season6 -1.131134 0.324077 -3.49 0.00058 ***
## season7 -2.111843 0.324092 -6.52 4.6e-10 ***
## season8 -2.964434 0.324111 -9.15 < 2e-16 ***
## season9 -2.842331 0.324132 -8.77 4.3e-16 ***
## season10 -2.761288 0.324156 -8.52 2.3e-15 ***
## season11 -1.882951 0.324183 -5.81 2.1e-08 ***
## season12 -1.199555 0.324212 -3.70 0.00027 ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.02 on 227 degrees of freedom
## Multiple R-squared: 0.786, Adjusted R-squared: 0.775
## F-statistic: 69.4 on 12 and 227 DF, p-value: <2e-16plot(forecast(ts_fit, h = 20))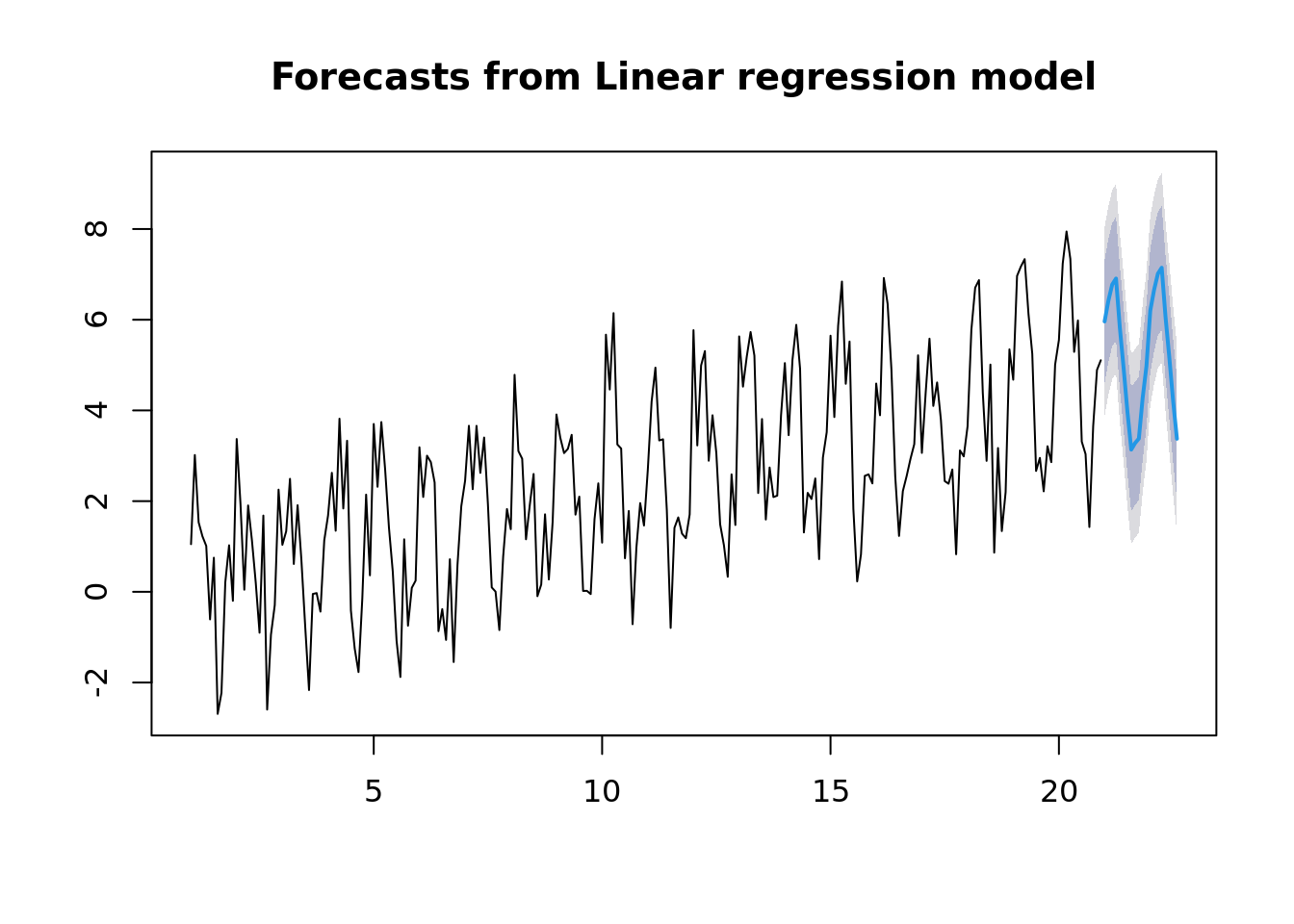
Now if you aren’t careful, it can automagically fit some fancy model. In this case, the STL+ETS(A,A,N). Is a combination of a Seasonal Trend with Loess and an Exponential smoothing state space model.
ts_fit <- stlf(all[,'seasonal_trend'])
plot(forecast(ts_fit))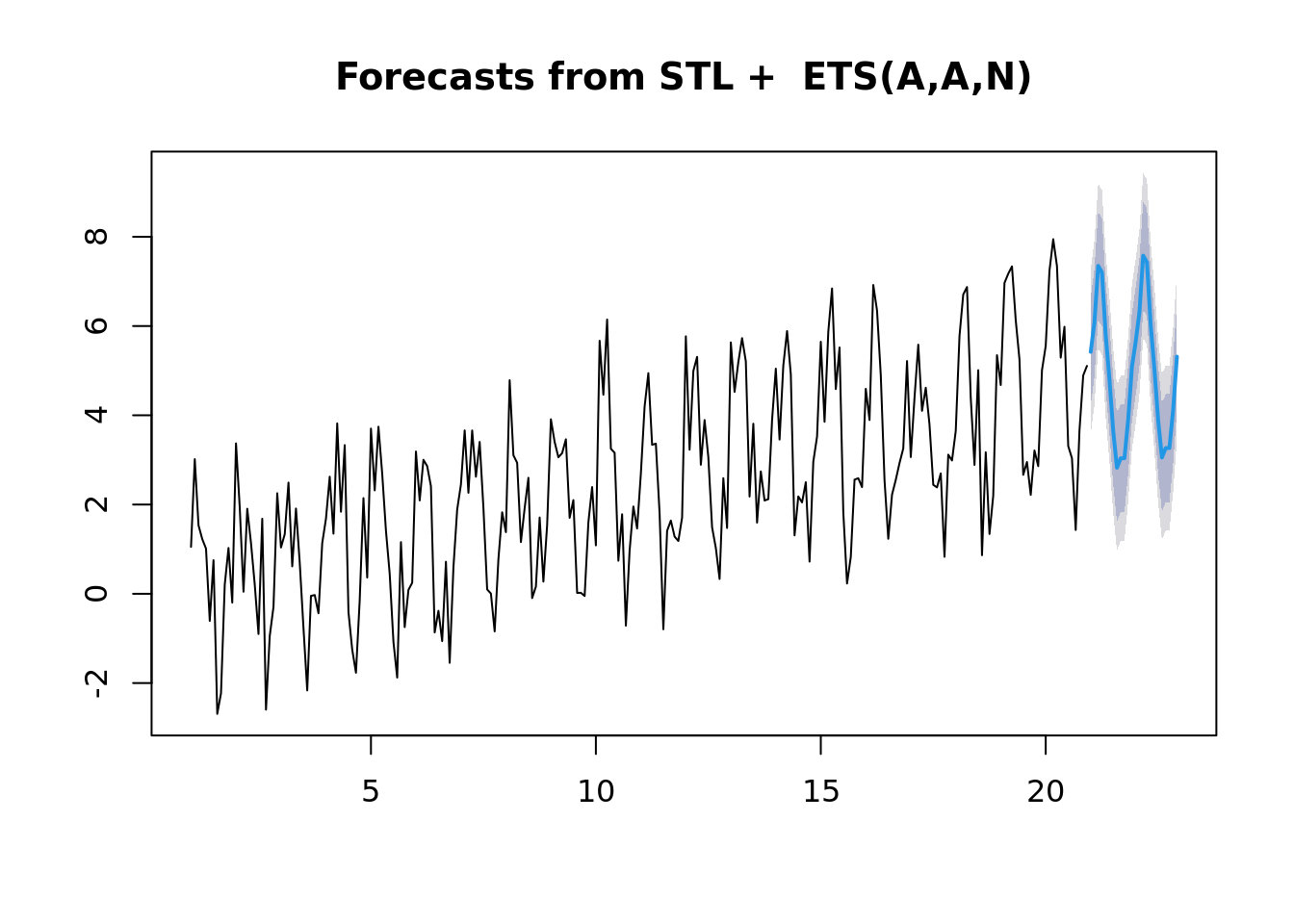
summary(ts_fit)##
## Forecast method: STL + ETS(A,A,N)
##
## Model Information:
## ETS(A,A,N)
##
## Call:
## ets(y = na.interp(x), model = etsmodel, allow.multiplicative.trend = allow.multiplicative.trend)
##
## Smoothing parameters:
## alpha = 0.0012
## beta = 1e-04
##
## Initial states:
## l = 0.2543
## b = 0.0196
##
## sigma: 0.943
##
## AIC AICc BIC
## 1293 1293 1311
##
## Error measures:
## ME RMSE MAE MPE MAPE MASE ACF1
## Training set -0.0213 0.935 0.763 -67.6 137 0.672 -0.128
##
## Forecasts:
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## Jan 21 5.42 4.21 6.63 3.573 7.27
## Feb 21 6.08 4.87 7.29 4.234 7.93
## Mar 21 7.35 6.14 8.56 5.500 9.20
## Apr 21 7.20 5.99 8.41 5.353 9.05
## May 21 5.80 4.59 7.01 3.953 7.65
## Jun 21 4.81 3.60 6.02 2.958 6.66
## Jul 21 3.66 2.45 4.86 1.807 5.50
## Aug 21 2.83 1.62 4.03 0.976 4.67
## Sep 21 3.04 1.83 4.25 1.188 4.89
## Oct 21 3.04 1.83 4.25 1.189 4.89
## Nov 21 3.91 2.70 5.11 2.057 5.75
## Dec 21 5.09 3.88 6.29 3.237 6.93
## Jan 22 5.65 4.44 6.86 3.802 7.50
## Feb 22 6.31 5.10 7.52 4.462 8.16
## Mar 22 7.58 6.37 8.79 5.728 9.43
## Apr 22 7.43 6.22 8.64 5.581 9.28
## May 22 6.03 4.82 7.24 4.181 7.88
## Jun 22 5.04 3.83 6.24 3.187 6.88
## Jul 22 3.88 2.68 5.09 2.035 5.73
## Aug 22 3.05 1.84 4.26 1.205 4.90
## Sep 22 3.27 2.06 4.47 1.417 5.11
## Oct 22 3.27 2.06 4.48 1.418 5.12
## Nov 22 4.13 2.93 5.34 2.286 5.98
## Dec 22 5.31 4.11 6.52 3.466 7.16plot(forecast(ts_fit, h = 20))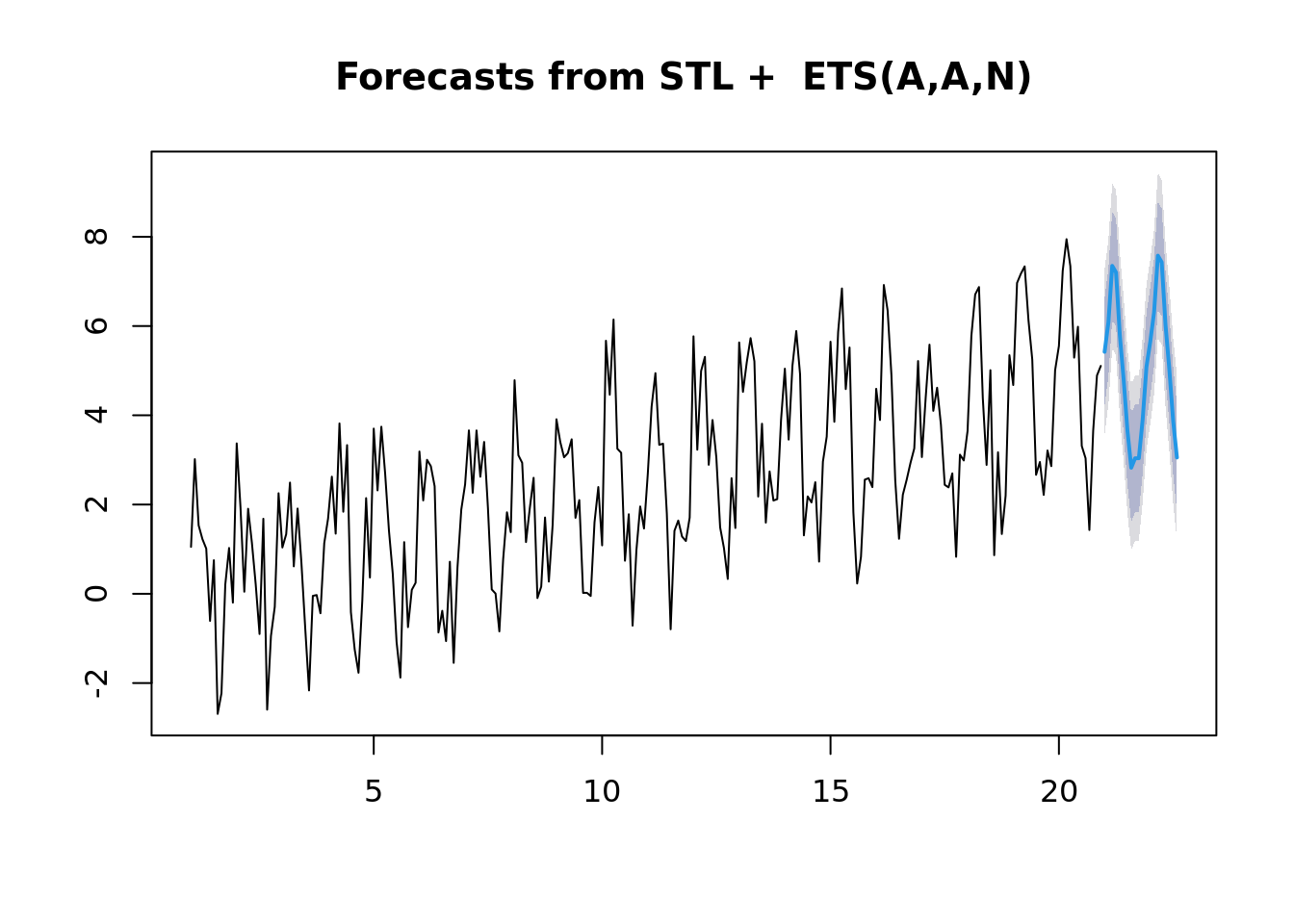
1.6 Your Turn - Some Actual Data!
1.6.1 Example 1: A twenty year history of weather in Maricopa, AZ
We looked at this lastweek.
These are daily statistics from ‘DayMet.’ Daymet isn’t actually observed data - it is ‘imputed’ data. So, it is available for everywhere in the continental US from 1980 on a 1km grid.
We will also use it in the model analysis lesson to compare this imputed ‘model’ data with ground truth observations.
You can learn more about it here: https://daymet.ornl.gov/ and Thornton et al 2021.
While we have a sample of the dataset in the lesson repository for a particular site, it is useful to know how to access the data for your site.
Just change the lat, lon, start and end times to look at your favorite site!
library(daymetr)
mac_daymet_list <- download_daymet(site = "Maricopa Agricultural Center",
lat = 33.068941,
lon = -111.972244,
start = 2000,
end = 2020, internal = TRUE)
# rename variables, create a date column
mac_daymet <- mac_daymet_list$data %>%
transmute(date = ymd(paste0(year, '01-01'))+ days(yday) -1,
precip = prcp..mm.day.,
tmax = tmax..deg.c.,
tmin = tmin..deg.c.,
tmean = (tmax + tmin) / 2,
trange = tmax - tmin,
srad = srad..W.m.2.,
vpd = vp..Pa.)
readr::write_csv(mac_daymet, file = '../data/mac_daymet.csv')Lets read in and look at the data
mac_daymet <- readr::read_csv('../data/mac_daymet.csv') %>%
select(date, precip, tmean, srad, vpd)## Rows: 7665 Columns: 8## ── Column specification ───────────────────────────────────
## Delimiter: ","
## dbl (7): precip, tmax, tmin, tmean, trange, srad, vpd
## date (1): date##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.head(mac_daymet)## # A tibble: 6 × 5
## date precip tmean srad vpd
## <date> <dbl> <dbl> <dbl> <dbl>
## 1 2000-01-01 0 12.2 203. 936.
## 2 2000-01-02 0 8.24 225. 680.
## 3 2000-01-03 0 6.72 284. 504.
## 4 2000-01-04 0 8.92 287. 582.
## 5 2000-01-05 0 8.86 292. 566.
## 6 2000-01-06 0 8.45 288. 566.tmean.ts <- ts(mac_daymet$tmean,
start = c(2000, 1),
end = c(2020, 365),
deltat = 1/365)
mac_ts <- ts(mac_daymet,
start = c(2000, 1),
end = c(2020, 365),
deltat = 1/365)Lets take a look
plot(tmean.ts, ylab = "Daily mean T", xlab = "Year")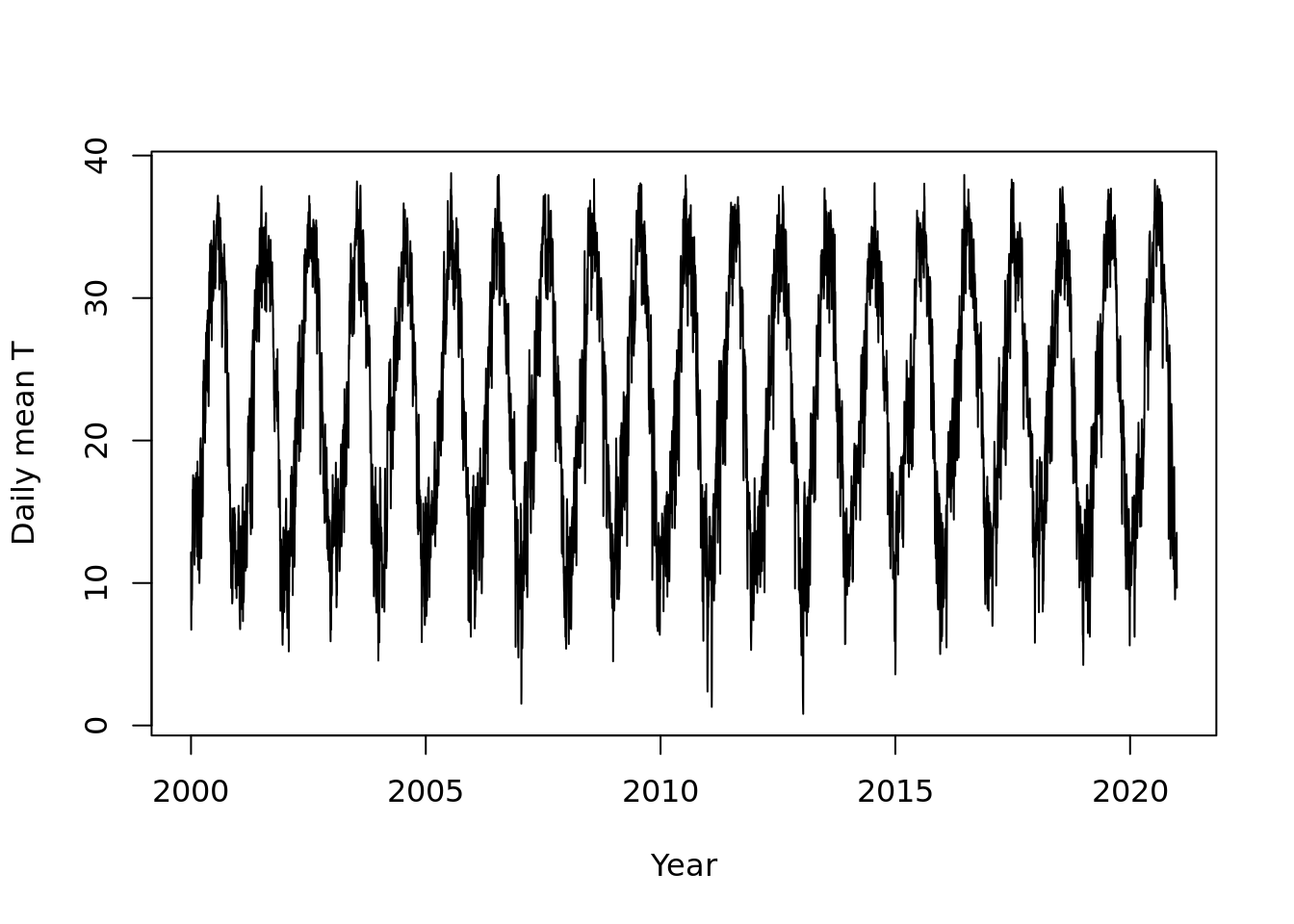
lag.plot(tmean.ts, set.lags = c(1, 10, 100, 180, 360))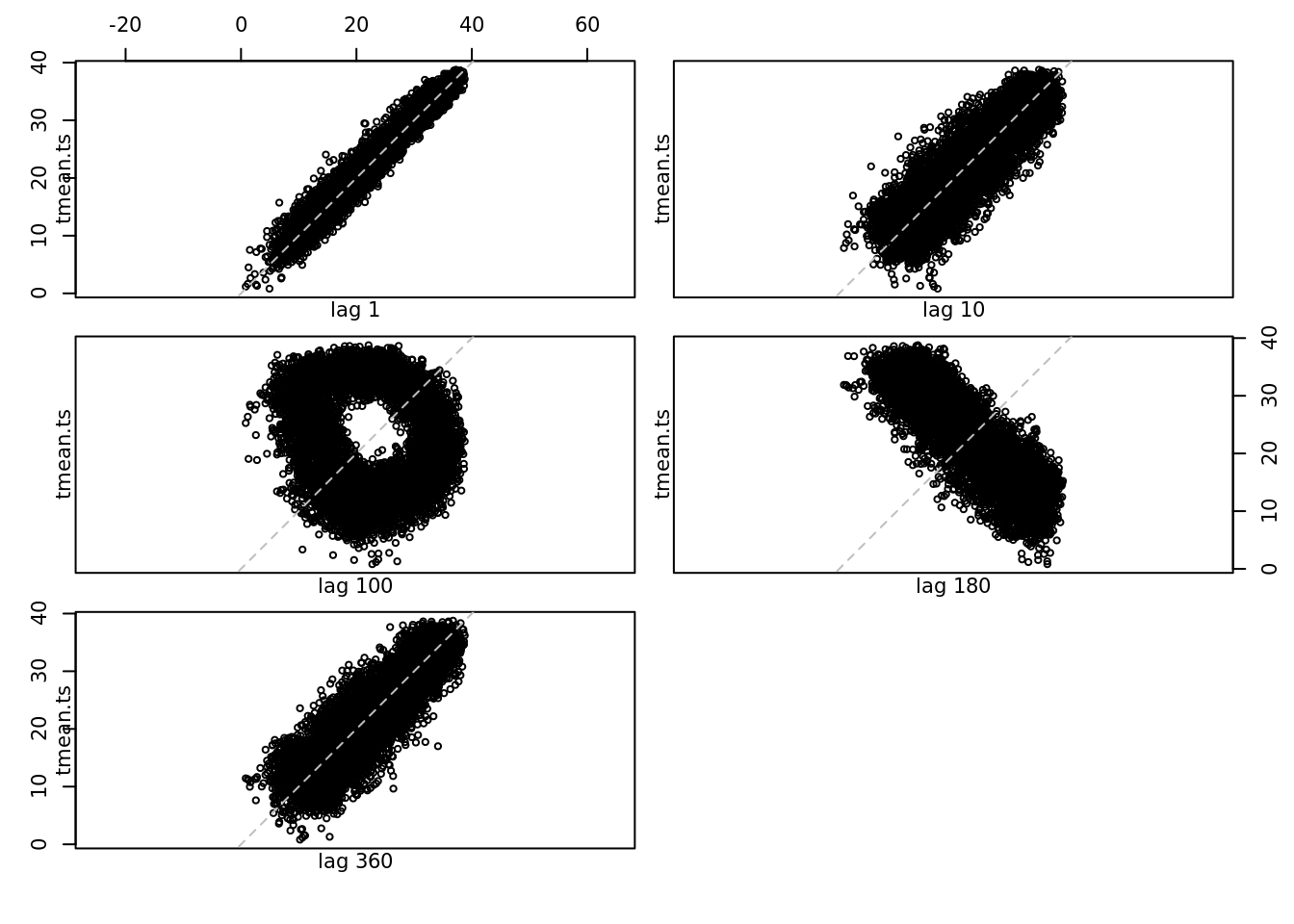
1.6.2 Autocorrelation
The lag plot shows the correlation between each point and the points at t+1. We can see that the interpolation between every other point.
Lets get some monthly temperature data and start working with that.
tmean_mo <- mac_daymet %>%
mutate(year = year(date), month = month(date)) %>%
group_by(year, month) %>%
summarise(tmean = mean(tmean), .groups = 'keep') %>%
ungroup() %>%
select(tmean)
tmean.mo.ts <- ts(tmean_mo, start = c(2000, 1), end = c(2020, 12), frequency = 12)
lag.plot(tmean.mo.ts, lags = 12)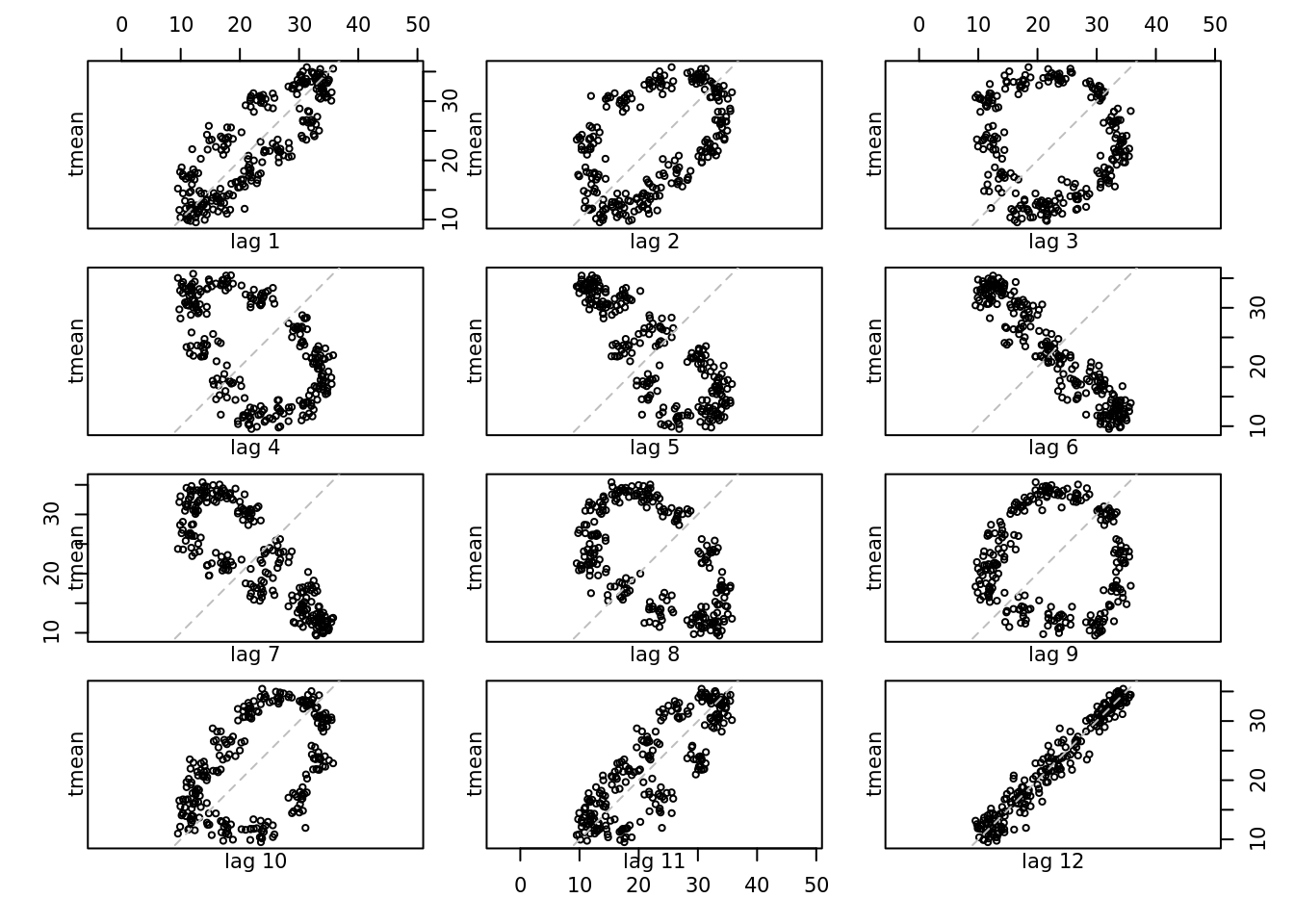
plot(acf(tmean.mo.ts))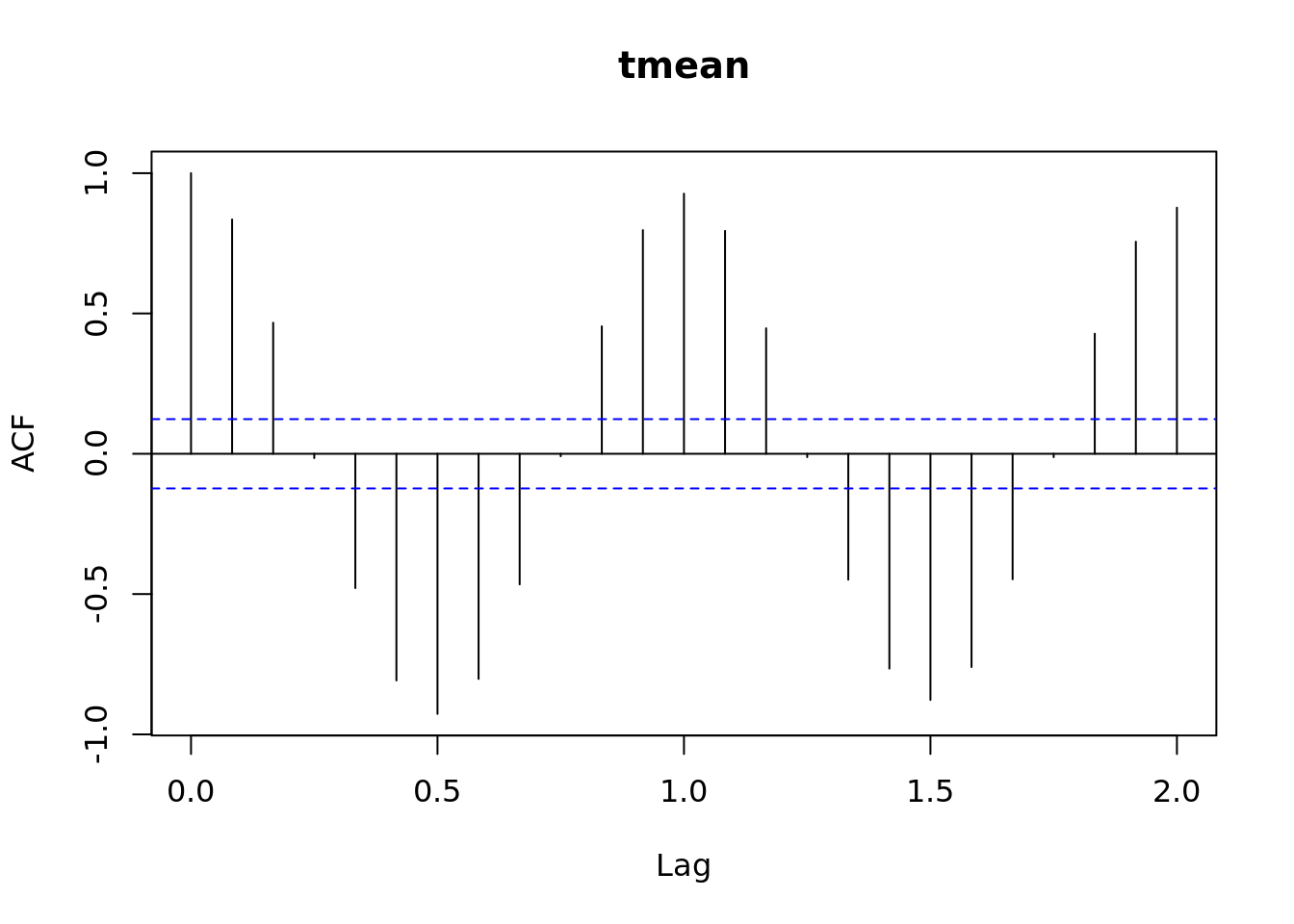
Your turn - decompose, plot, look at a lag plot, acf, fit using auto.arima.
which of the other variables are similar to temperature? Which are most different?
vpd_mo <- mac_daymet %>%
mutate(year = year(date), month = month(date)) %>%
group_by(year, month) %>%
summarise(vpd = mean(vpd), .groups = 'keep') %>%
ungroup() %>%
select(vpd)
lag.plot(vpd_mo, lags = 12)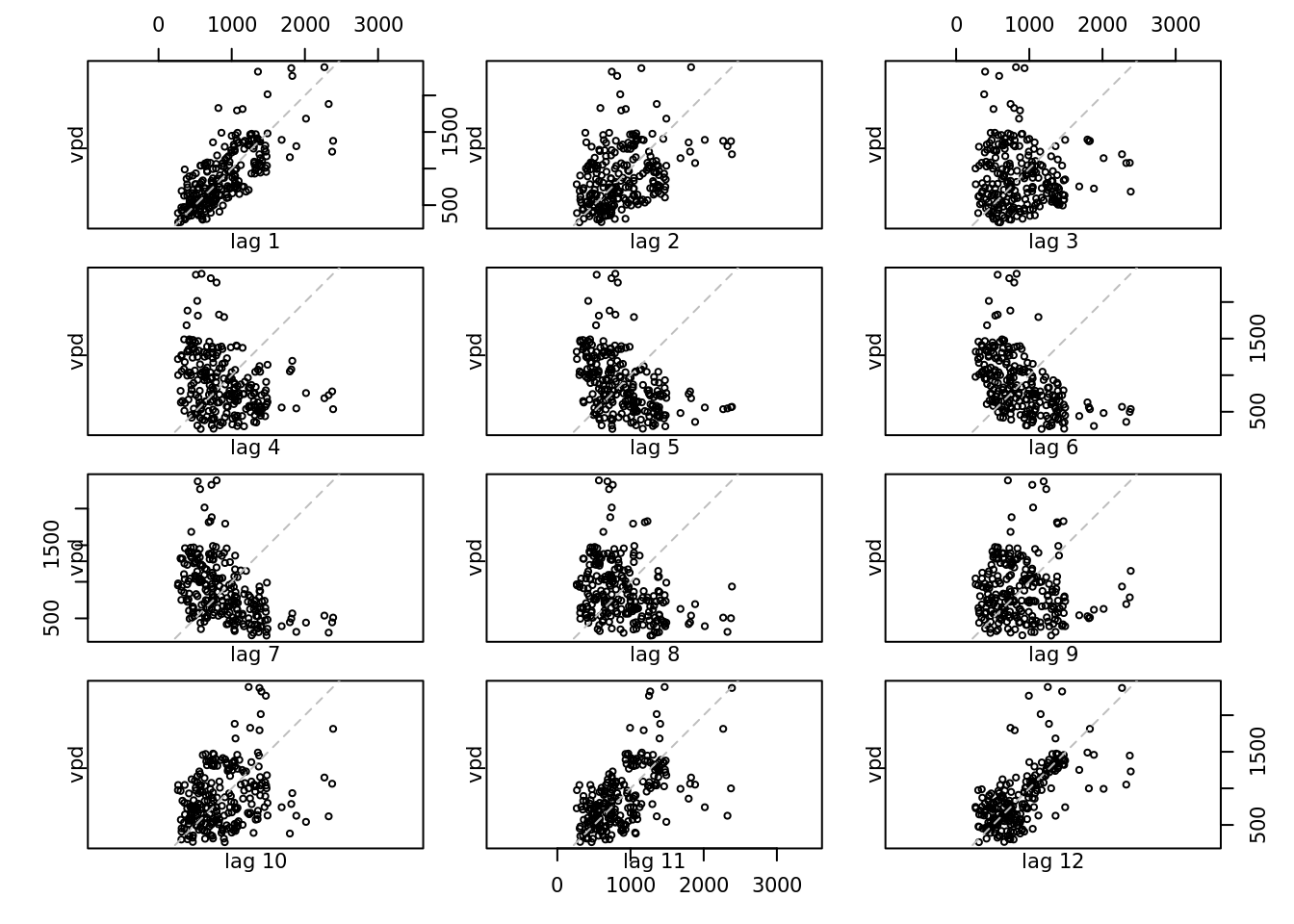
acf(vpd_mo)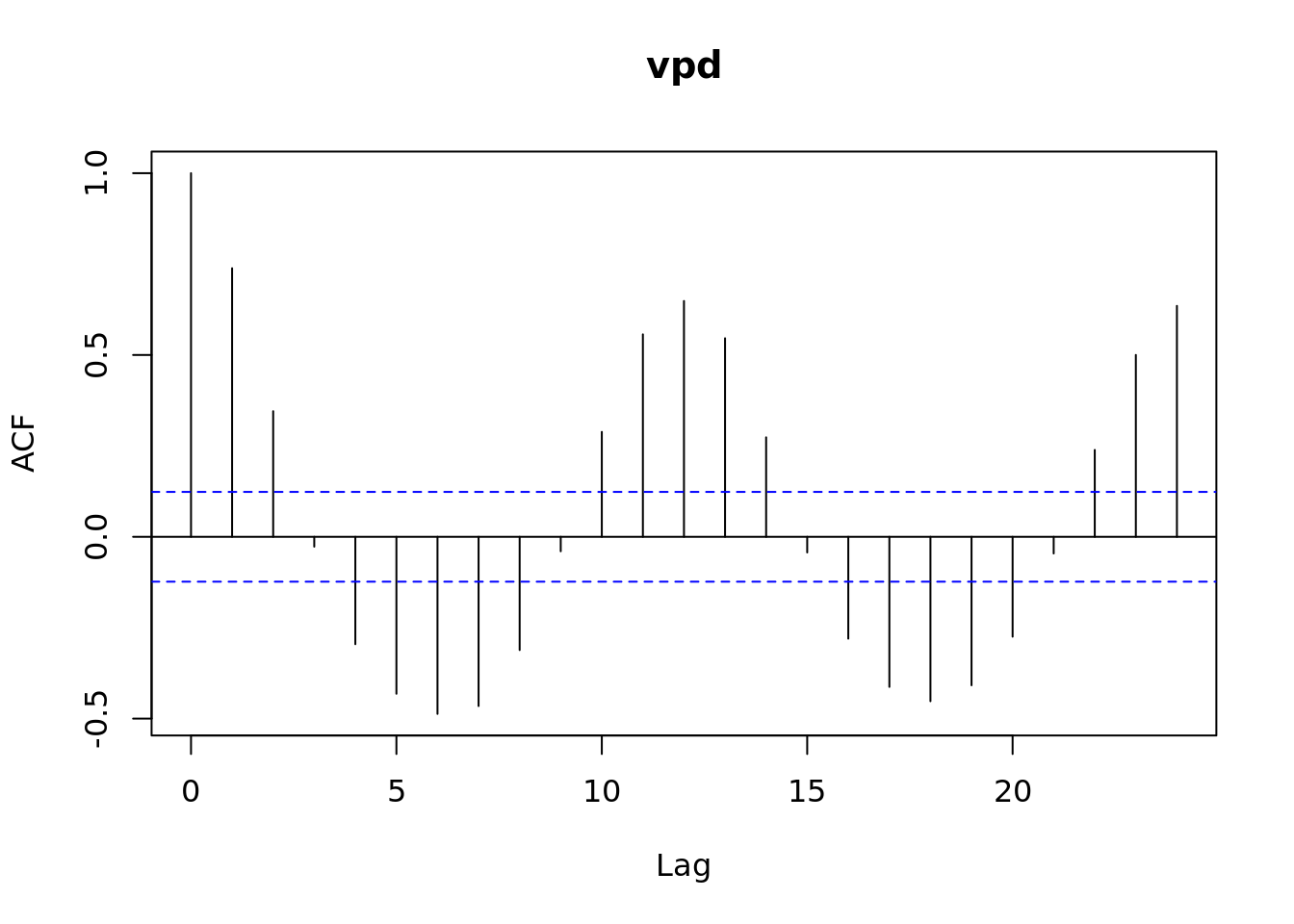
ccf(tmean_mo, vpd_mo)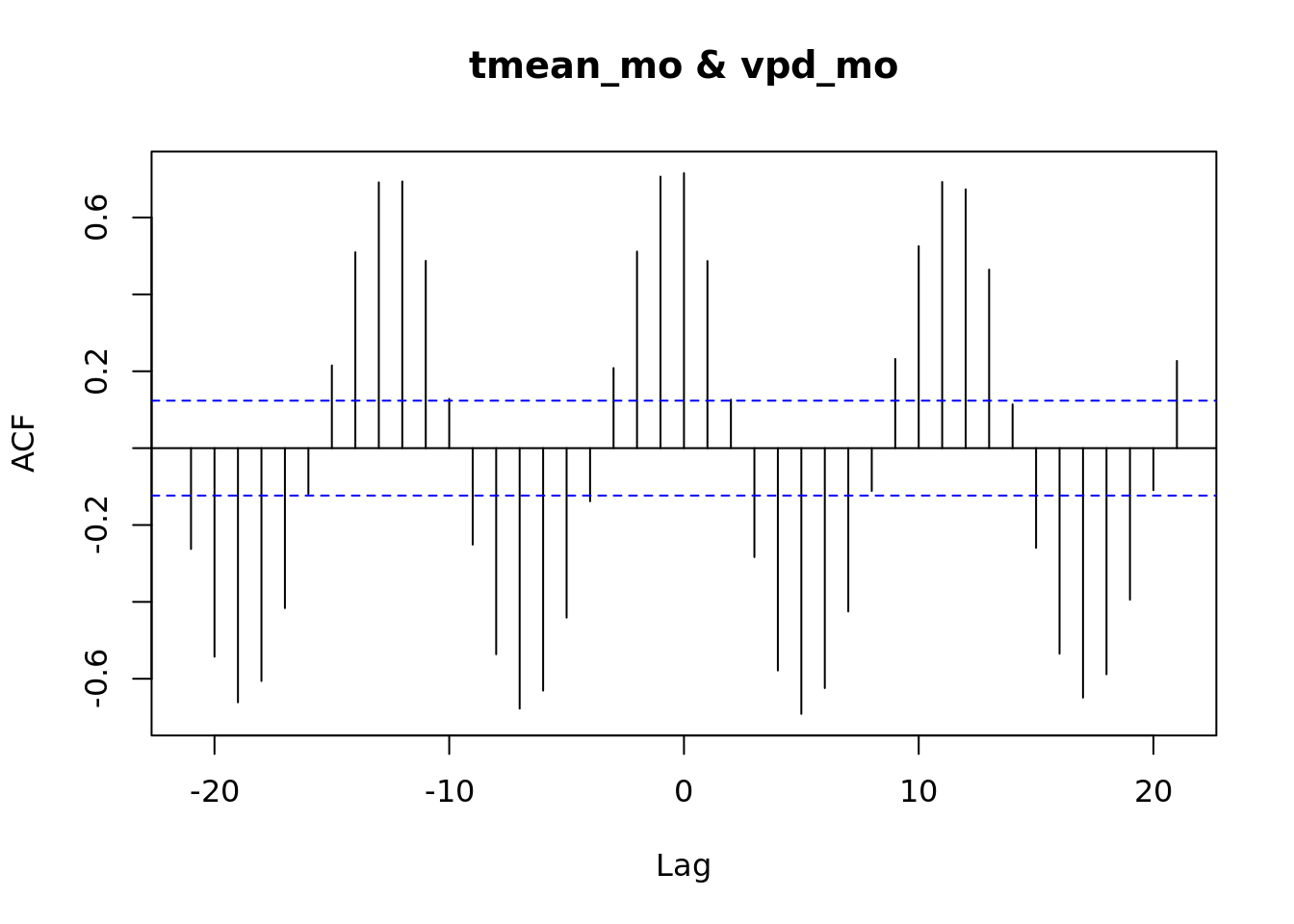
ma_tmean <- ma(tmean.mo.ts, order = 13, centre = TRUE)
plot(ma_tmean, xlab = 'Year', ylab = 'trend')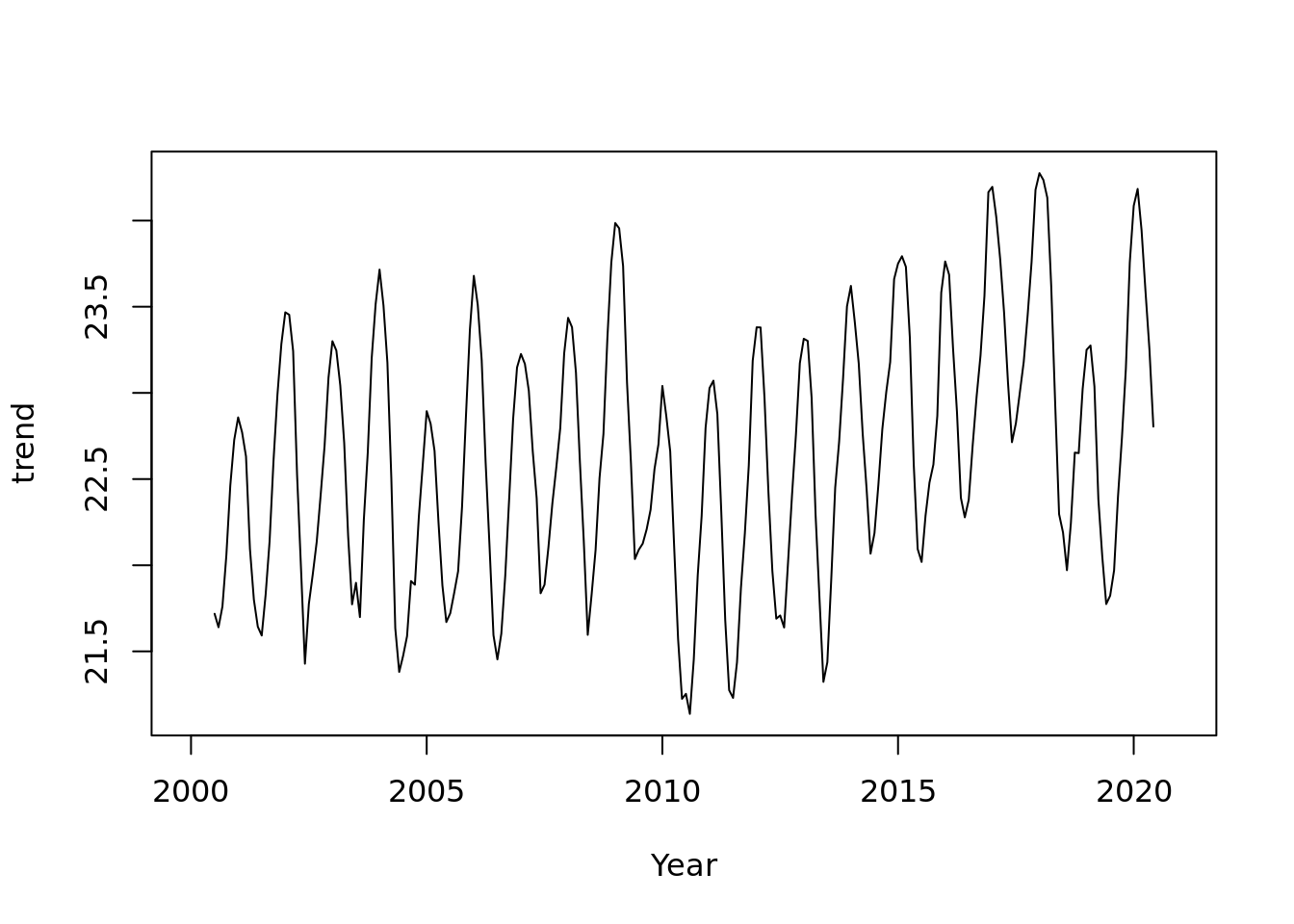
plot(tmean.mo.ts) +
lines(ma_tmean)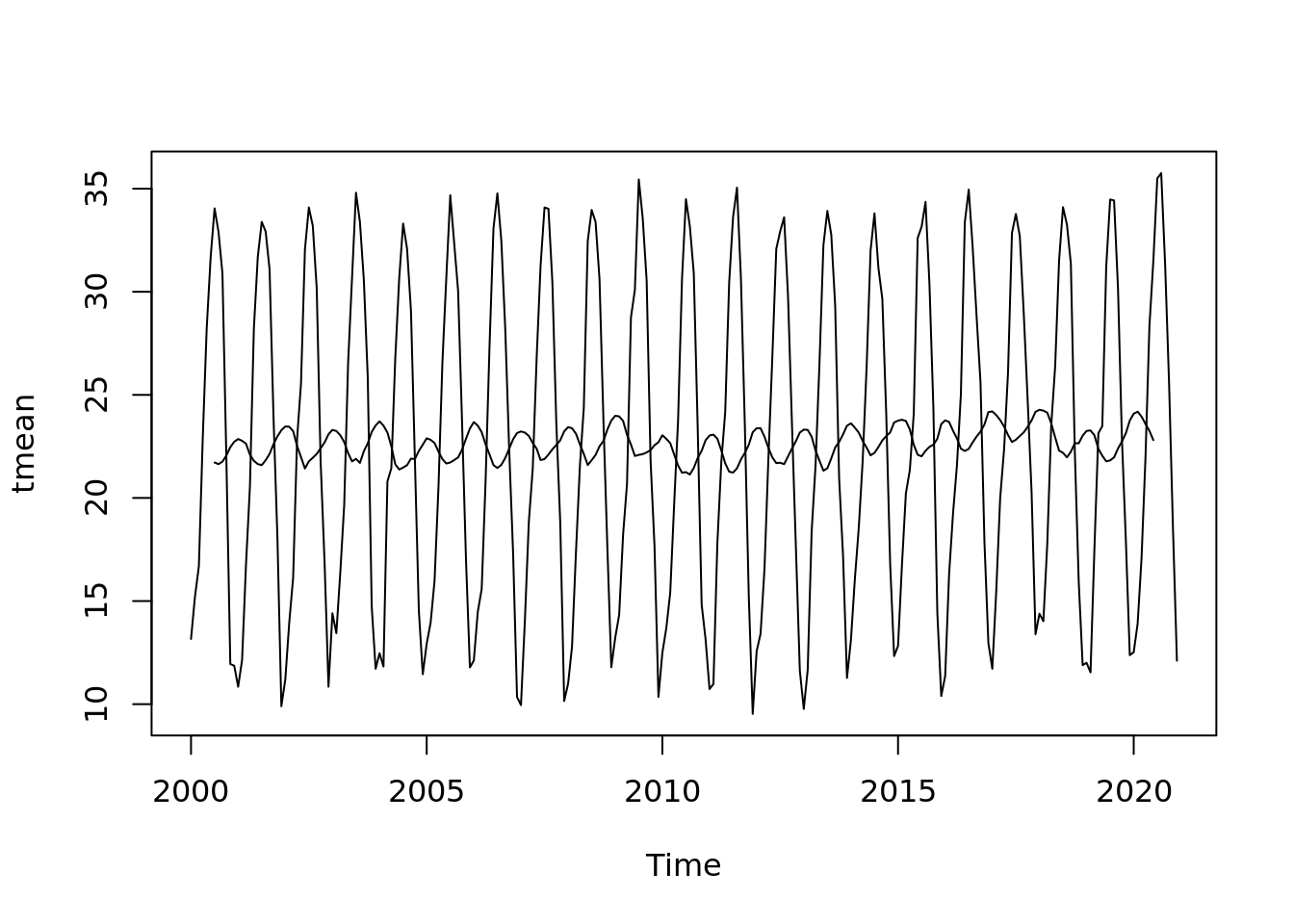
## integer(0)plot(tmean.mo.ts - ma_tmean)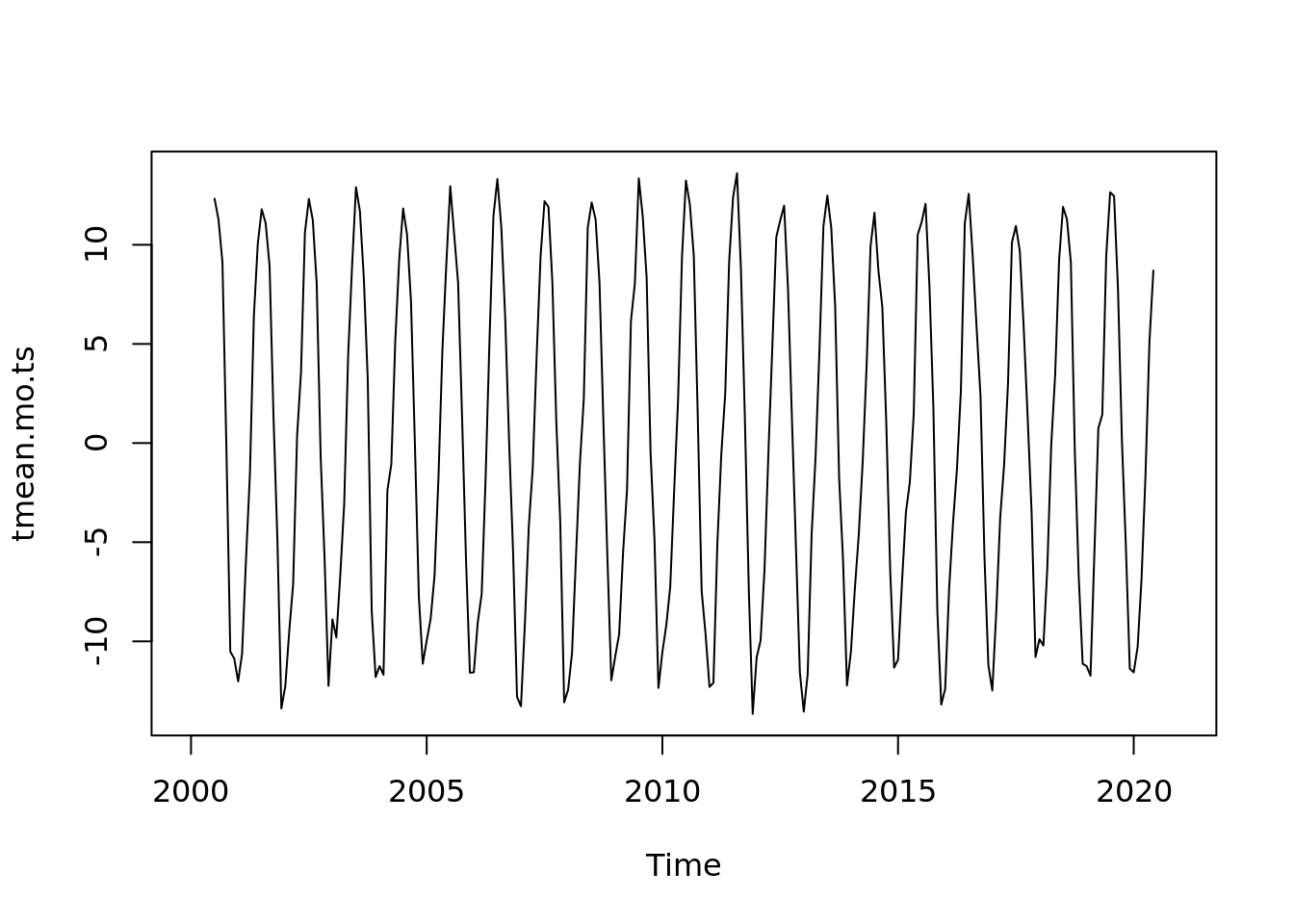
plot(ma_tmean)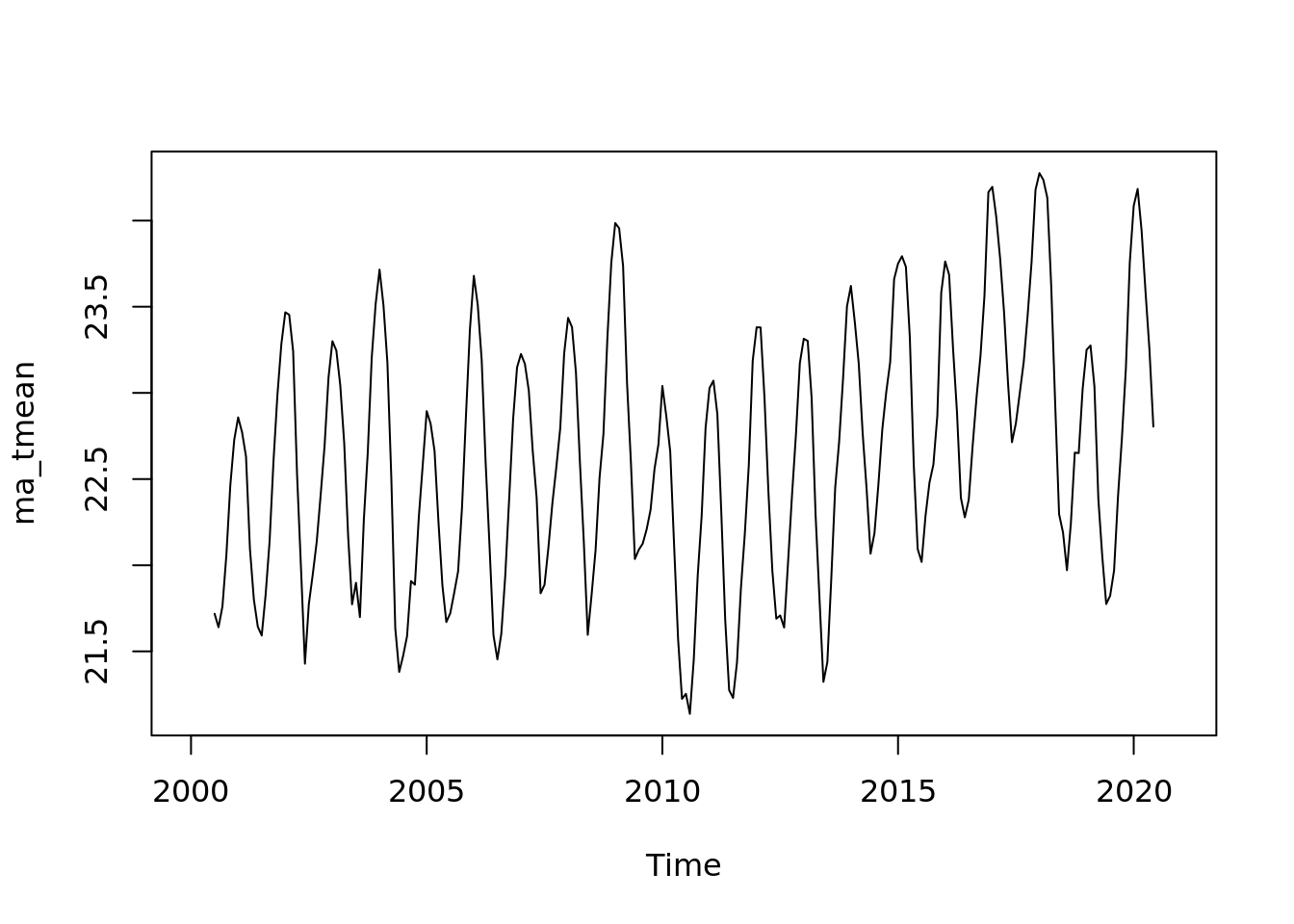
acf(tmean.ts, lag.max = 180)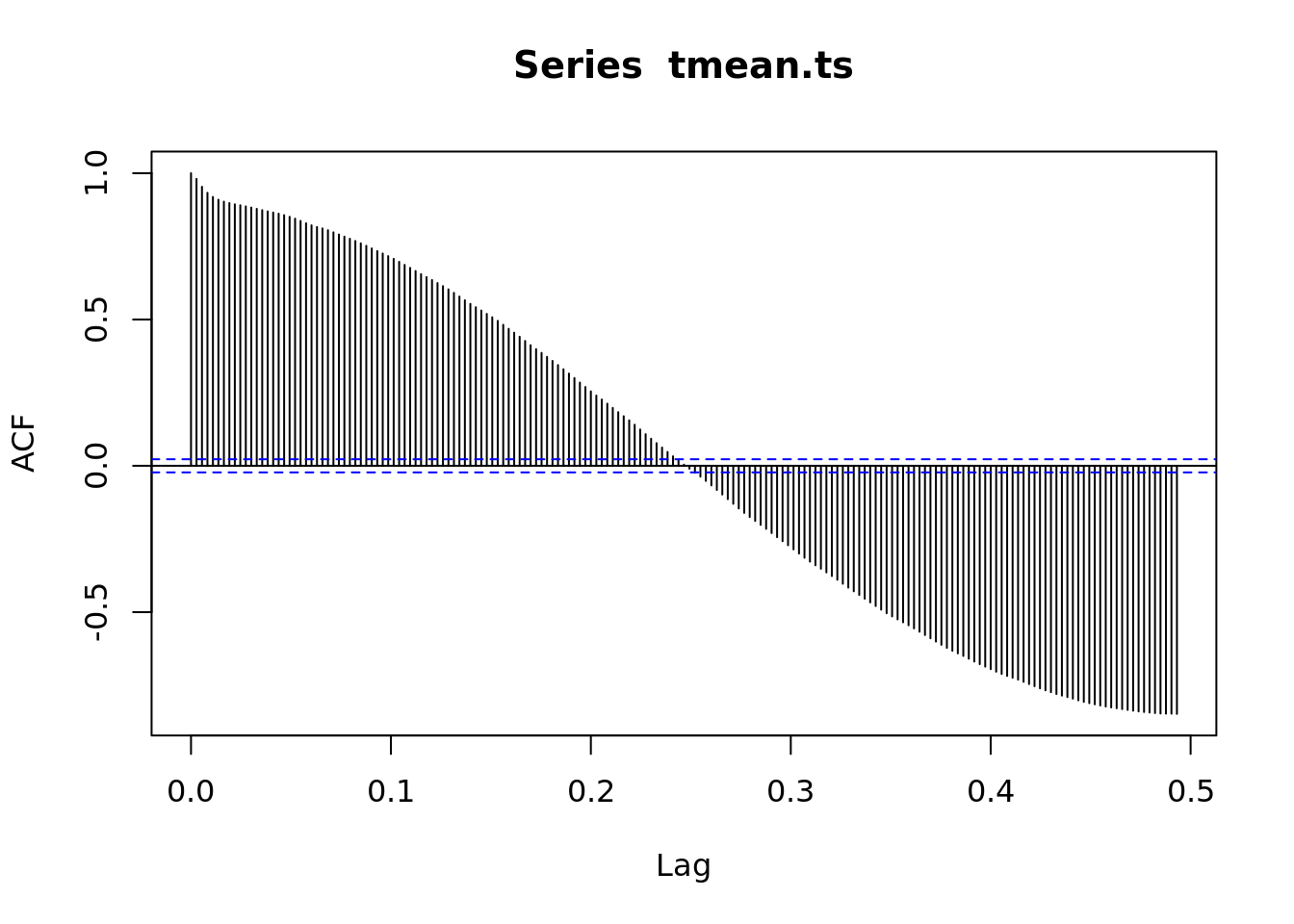
# What does this mean?
lag.plot(tmean.ts)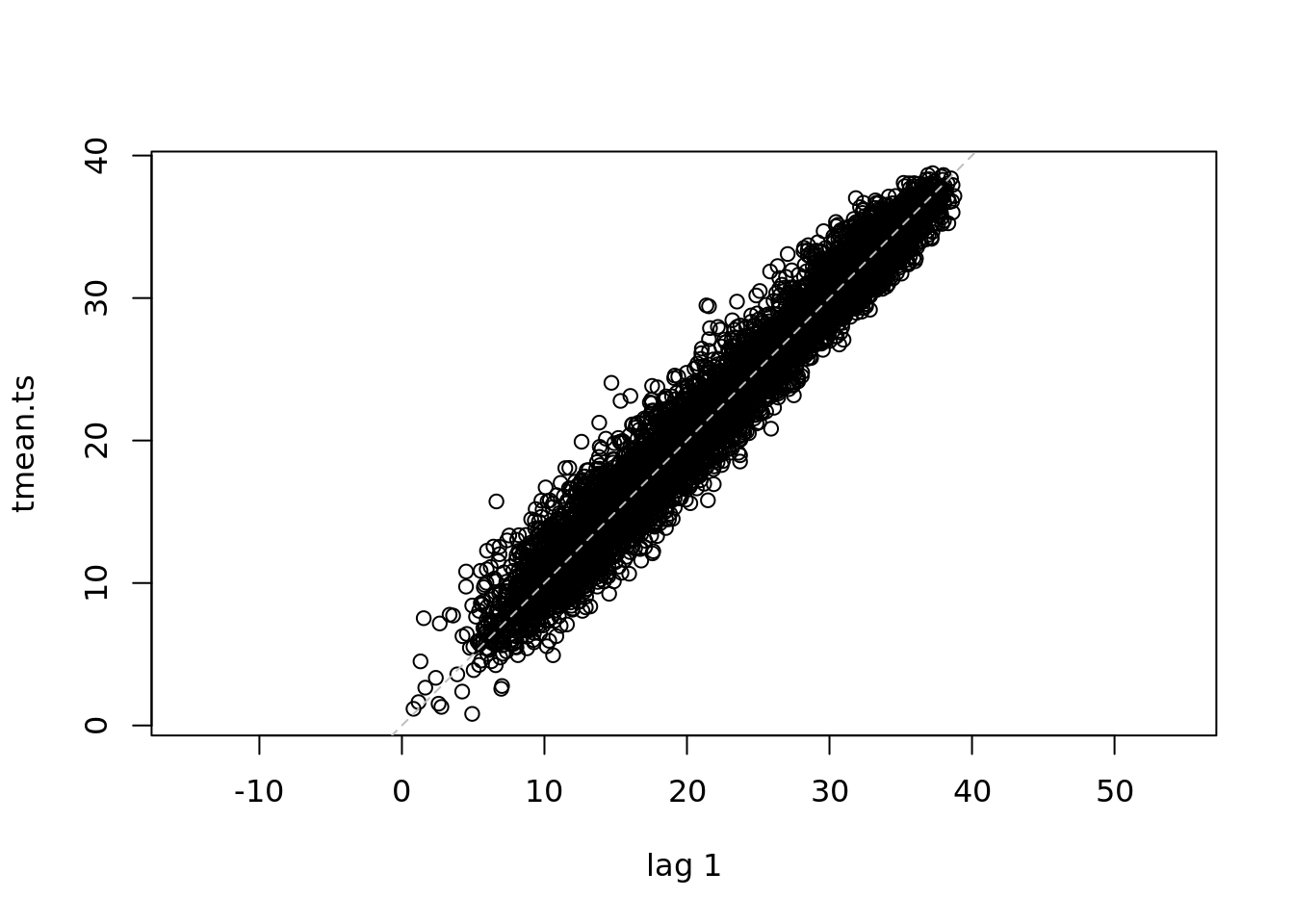
Your Turn:
Plot a few of the other variables. How do the seasonal patterns and trends compare?
precip.ts <- ts(mac_daymet$precip,
start = c(2000, 1),
end = c(2020, 365),
deltat = 1/365)
lag.plot(precip.ts)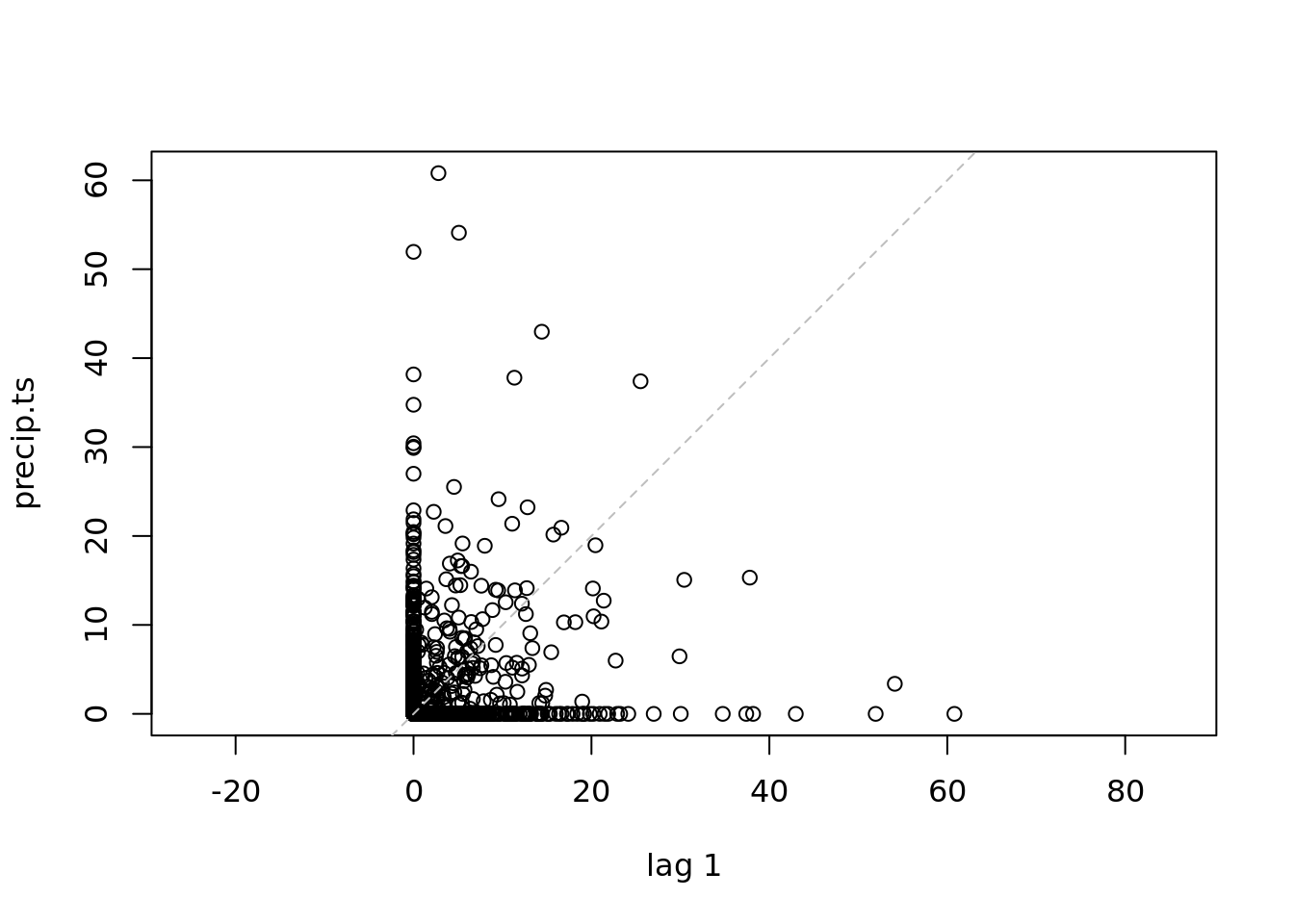
vpd.ts <- ts(mac_daymet$vpd,
start = c(2000, 1),
end = c(2020, 365),
deltat = 1/365)
lag.plot(vpd.ts, )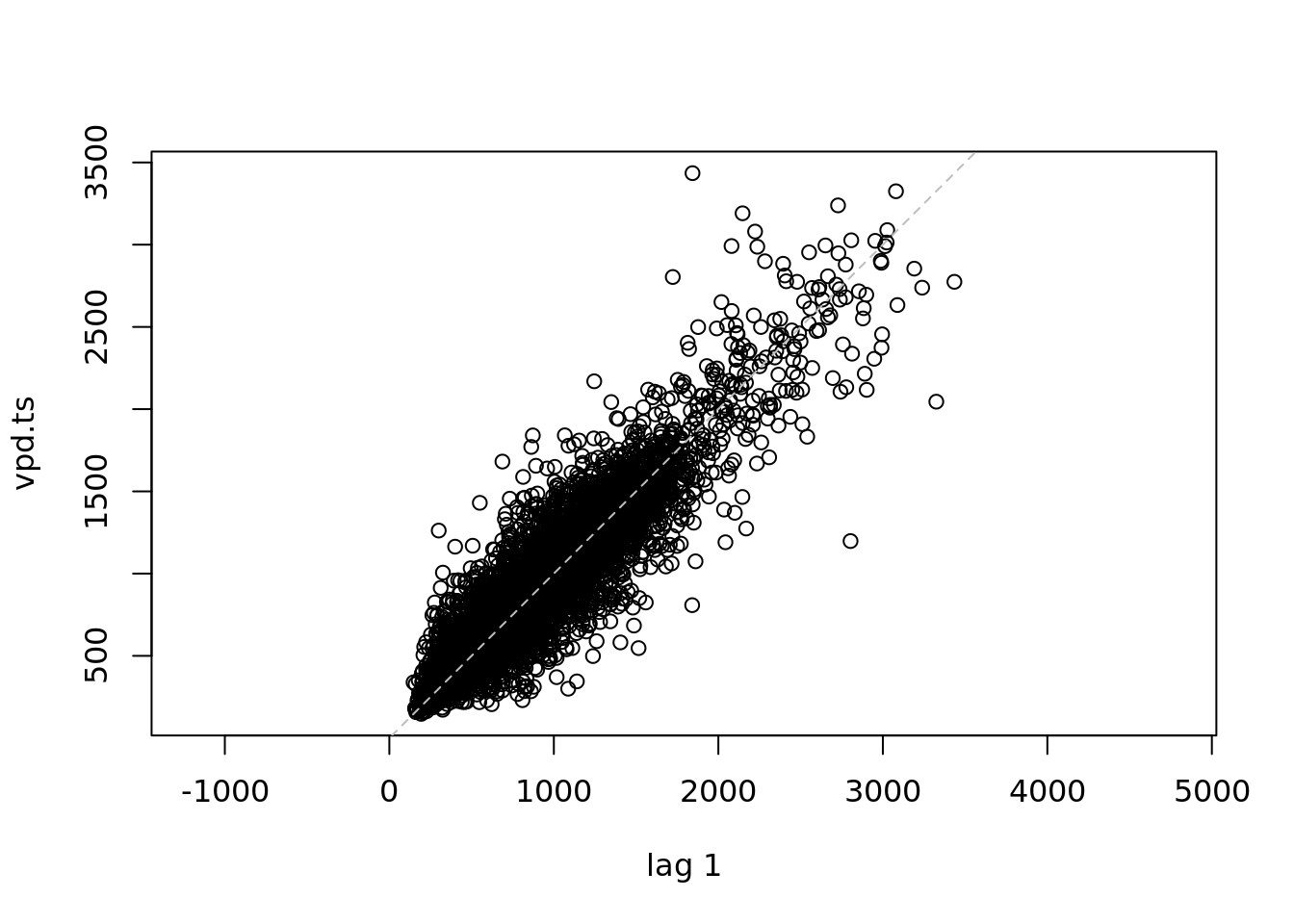
all.ts <- ts(mac_daymet,
start = c(2000, 1),
end = c(2020, 365),
deltat = 1/365)
lag.plot(all.ts)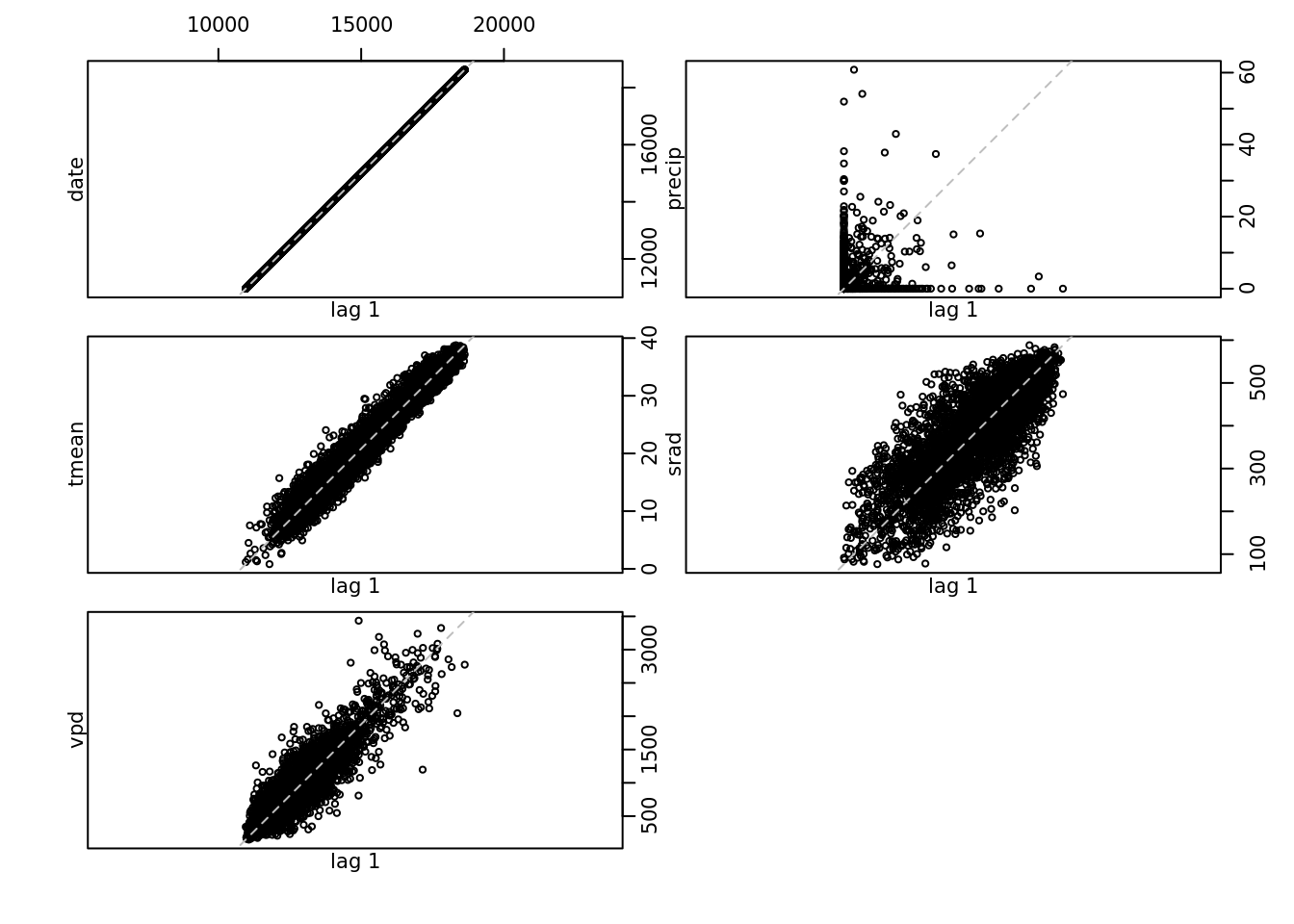
ccf(vpd.ts, precip.ts)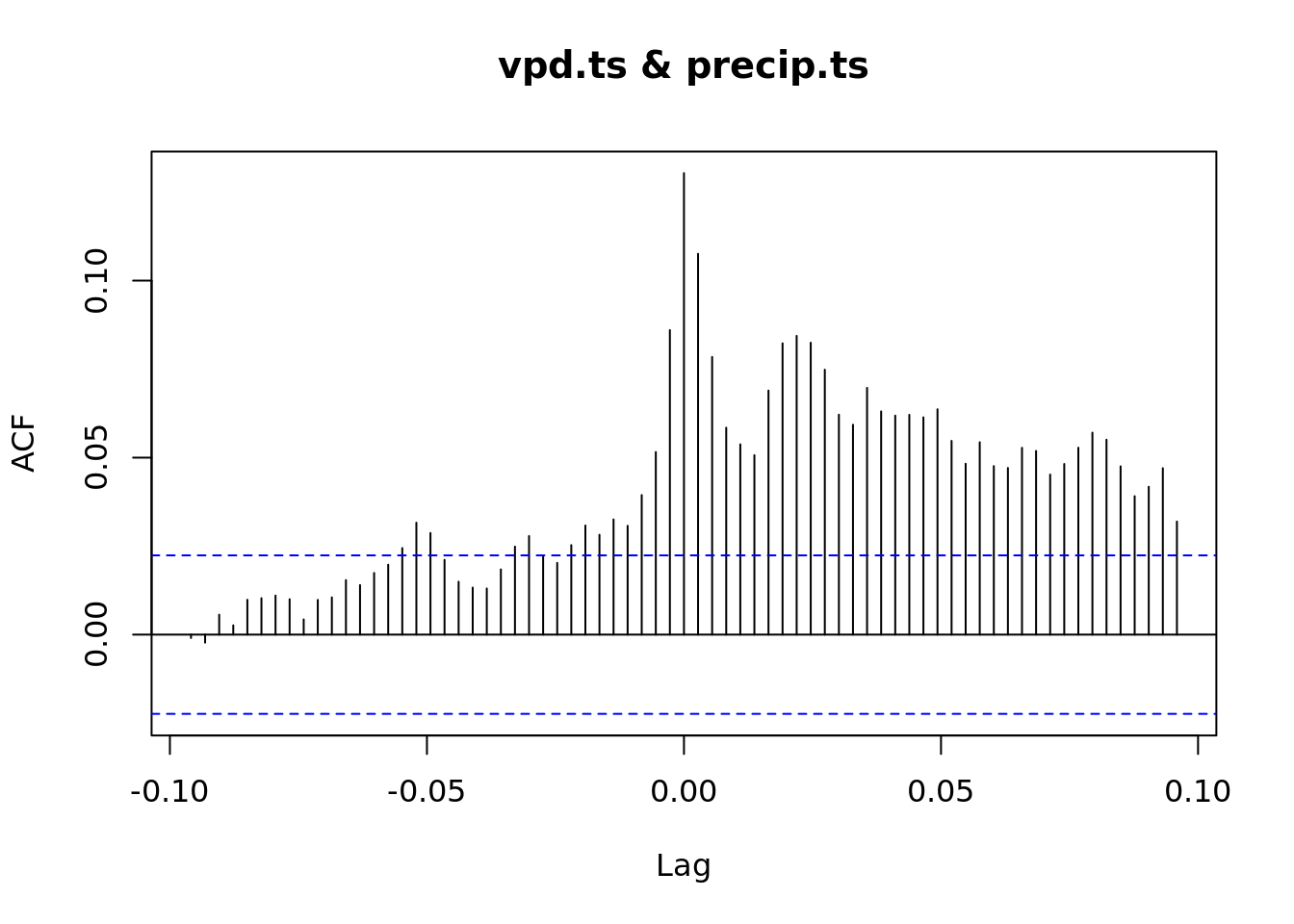
ccf(precip.ts, tmean.ts)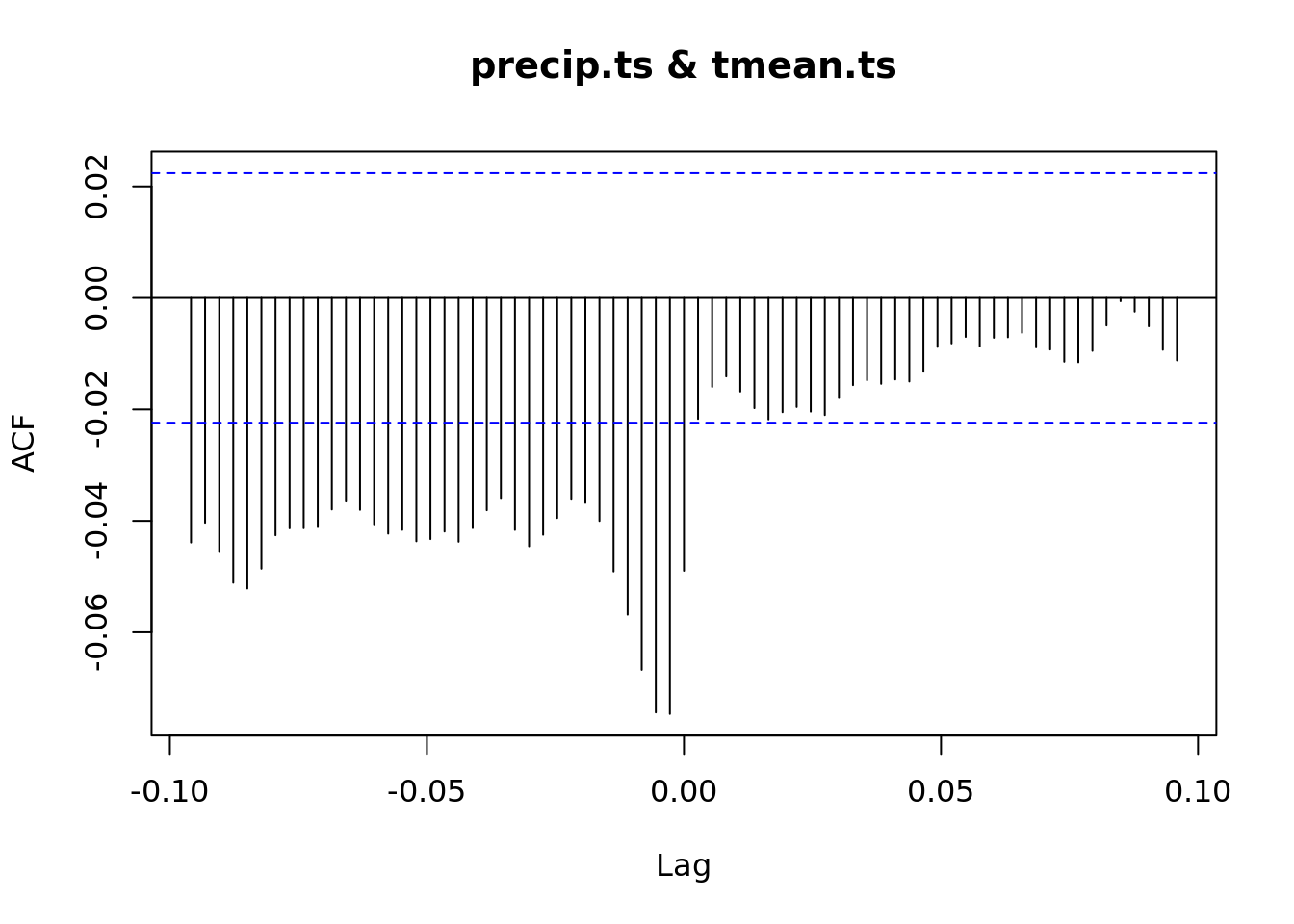
https://cals.arizona.edu/azmet/06.htm https://cals.arizona.edu/azmet/raw2003.htm
head(mac_daymet)## # A tibble: 6 × 5
## date precip tmean srad vpd
## <date> <dbl> <dbl> <dbl> <dbl>
## 1 2000-01-01 0 12.2 203. 936.
## 2 2000-01-02 0 8.24 225. 680.
## 3 2000-01-03 0 6.72 284. 504.
## 4 2000-01-04 0 8.92 287. 582.
## 5 2000-01-05 0 8.86 292. 566.
## 6 2000-01-06 0 8.45 288. 566.mac_azmet <- readr::read_csv('https://cals.arizona.edu/azmet/data/0620rd.txt',
col_select = 1:4,
col_names = c('year', 'day', 'hour', 'air_temp')) %>%
mutate(doy = day + hour/24)## Rows: 366 Columns: 4## ── Column specification ───────────────────────────────────
## Delimiter: ","
## dbl (4): year, day, hour, air_temp##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.a <- acf(mac_azmet$air_temp)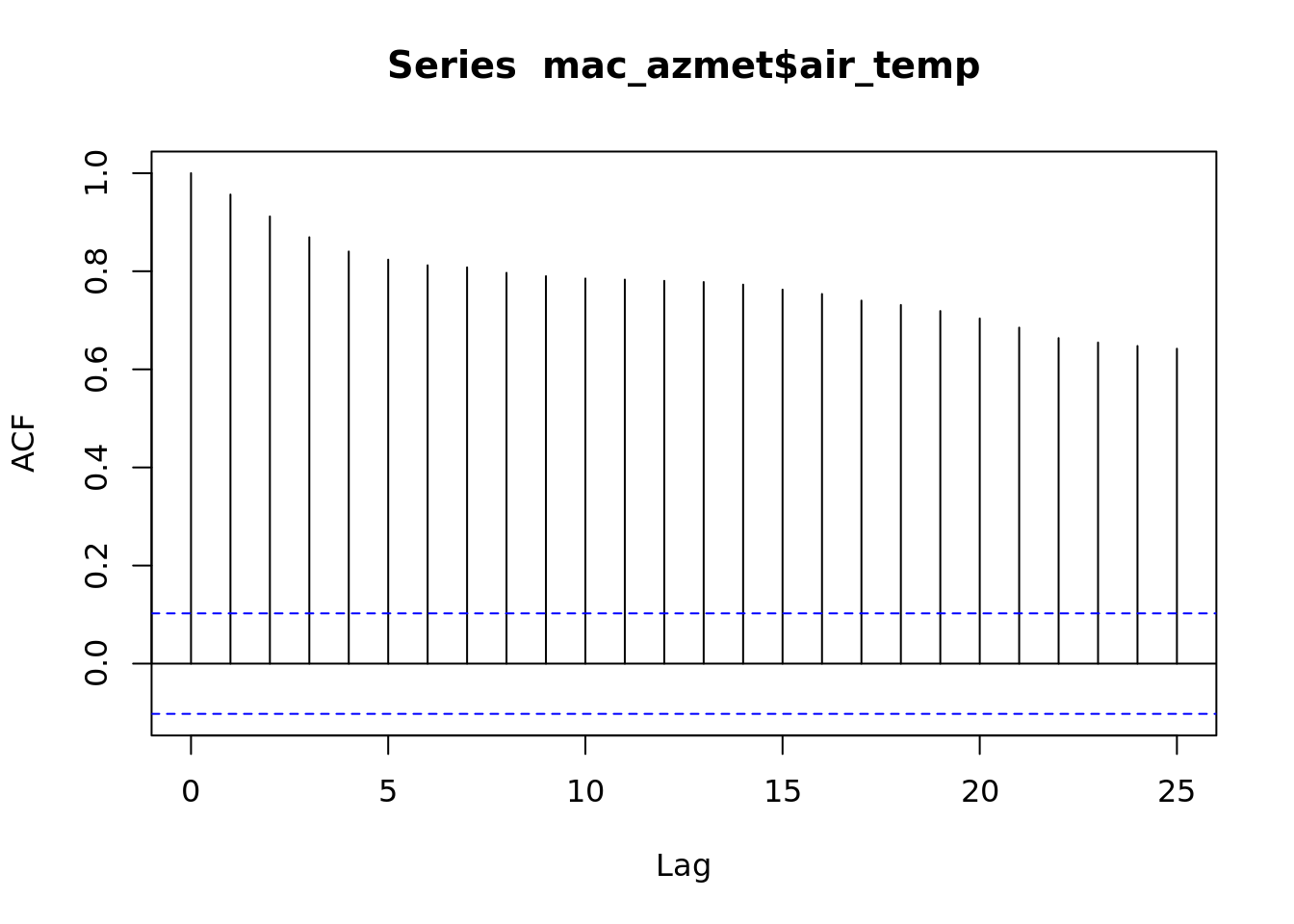
1.7 Growth Curves
This is from the NEON Ecological Forecasting Initiative Challenge
library(ggplot2)
library(tidyr)
gcc <- readr::read_csv('https://data.ecoforecast.org/targets/phenology/phenology-targets.csv.gz')## Rows: 14320 Columns: 6## ── Column specification ───────────────────────────────────
## Delimiter: ","
## chr (1): siteID
## dbl (4): gcc_90, rcc_90, gcc_sd, rcc_sd
## date (1): time##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.gcc_wide <- gcc %>%
dplyr::select(time, siteID, gcc_90) %>%
pivot_wider(id_cols = time, names_from = siteID, values_from = gcc_90)
head(gcc_wide)## # A tibble: 6 × 9
## time HARV BART SCBI STEI UKFS GRSM DELA
## <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2016-12-13 0.329 NA 0.325 NA NA NA NA
## 2 2016-12-14 0.328 0.344 0.325 NA NA NA NA
## 3 2016-12-15 0.330 0.346 0.326 NA NA NA NA
## 4 2016-12-16 0.329 0.342 0.326 NA NA NA 0.345
## 5 2016-12-17 0.332 0.350 0.326 NA NA NA 0.349
## 6 2016-12-18 0.332 0.348 0.327 NA NA NA 0.347
## # … with 1 more variable: CLBJ <dbl>ggplot(gcc, aes(time, gcc_90)) +
geom_line() +
facet_wrap(~siteID)## Warning: Removed 1 row(s) containing missing values
## (geom_path).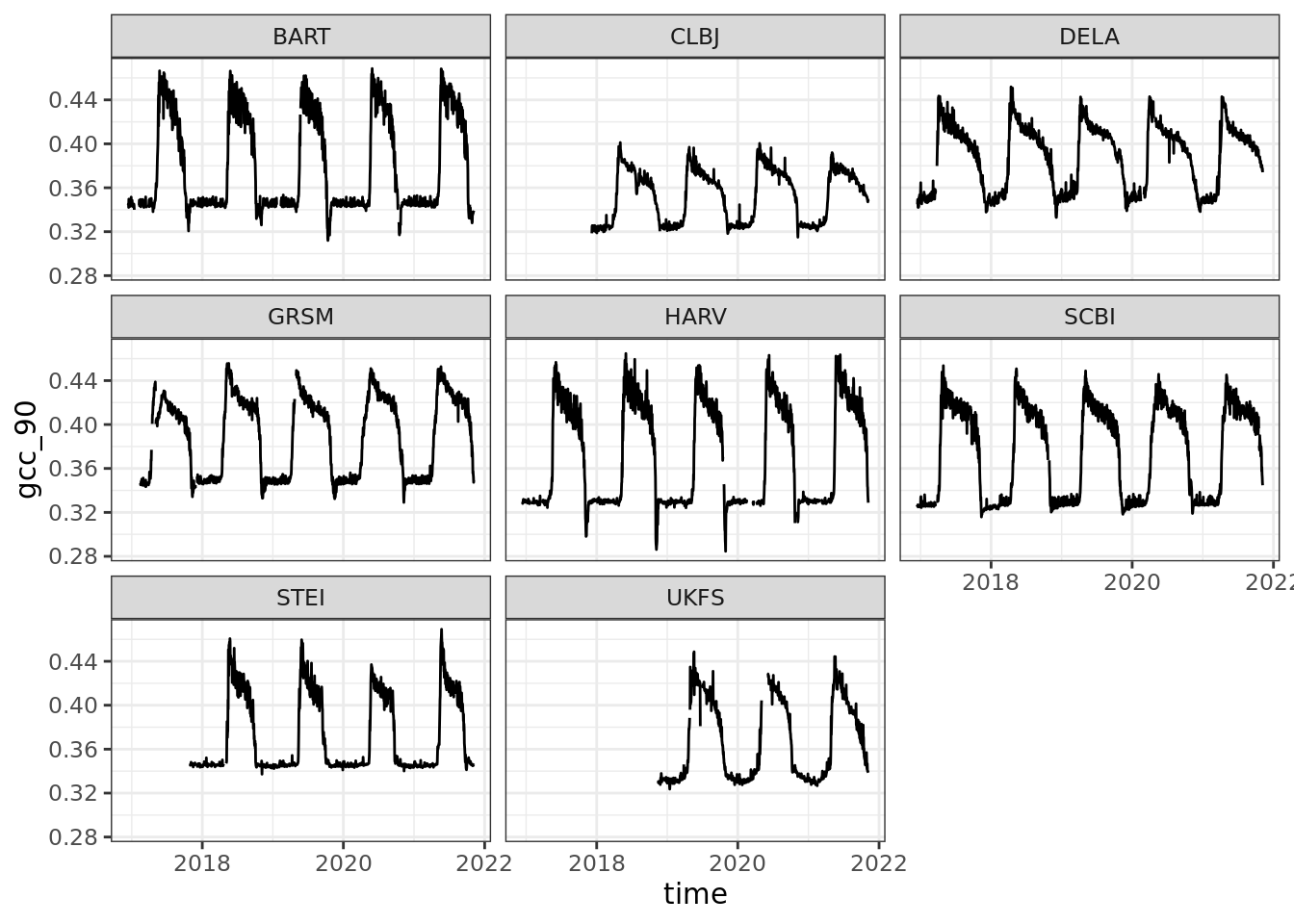
gcc_ts <- ts(gcc_wide$BART, frequency = 365)
plot(gcc_ts)
gcc_ts_interp <- na.interp((gcc_ts))
plot(decompose(gcc_ts_interp))
plot(forecast(gcc_ts))
f <- auto.arima(gcc_ts)
plot(f)1.8 References
Daymet
Thornton, M.M., R. Shrestha, Y. Wei, P.E. Thornton, S. Kao, and B.E. Wilson. 2020. Daymet: Daily Surface Weather Data on a 1-km Grid for North America, Version 4. ORNL DAAC, Oak Ridge, Tennessee, USA. https://doi.org/10.3334/ORNLDAAC/1840
Daymet: Daily Surface Weather Data on a 1-km Grid for North America, Version 4 https://doi.org/10.3334/ORNLDAAC/1840
Some of the material is based on the following courses and texts
Ben Bolker 2007 Ecological Models and Data in R. Princeton university press. - The author makes a early version pre-print available on his website https://ms.mcmaster.ca/~bolker/emdbook/book.pdf
Ethan White and Morgan Earnst Ecological Dynamics and Forecasting https://github.com/weecology/forecasting-course - Dietze, Michael. Ecological forecasting. Princeton University Press, 2017. - Dietze, Michael. Ecological forecasting. Course materials https://github.com/EcoForecast/EF_Activities
Hyndman, R.J., & Athanasopoulos, G. (2018) Forecasting: principles and practice, 2nd edition, OTexts: Melbourne, Australia. OTexts.com/fpp2. Accessed on 2021-10-31
Dietze, Michael C., et al. “Iterative near-term ecological forecasting: Needs, opportunities, and challenges.” Proceedings of the National Academy of Sciences 115.7 (2018): 1424-1432. https:doi.org/10.1073/pnas.1710231115