6 Session 6: Reproducible workflows revisited
6.1 Workflows and Continuous Integration
6.1.1 Learning Outcomes
- Conceptualize workflows for reproducible processing
- Understand how workflow systems can simplify repetitive tasks
- Overview systems for executing workflows
- Understand the utility of continuous integration
6.1.2 Introduction
Preparing data for running analysis, models, and visualization processes can be complex, with many dependencies among datasets, as well as complex needs for data cleaning, munging, and integration that need to occur before “analysis” can begin.
Many research projects would benefit from a structured approach to organizing these processes into workflows. A research workflow is an ordered sequence of steps in which the outputs of one process are connected to the inputs of the next in a formal way. Steps are then chained together to typically create a directed, acyclic graph that represents the entire data processing pipeline.
 This hypothetical workflow shows three processing stages for downloading, integrating, and mapping the
data, along with the outputs of each step. This is a simplified rendition of what is normally a much more
complex process.
This hypothetical workflow shows three processing stages for downloading, integrating, and mapping the
data, along with the outputs of each step. This is a simplified rendition of what is normally a much more
complex process.
Whether simple or complex, it is helpful to conceptualize your entire workflow as a directed graph, which helps to identify the explicit and implicit dependencies, and to plan work collaboratively.
6.1.3 Workflow dependencies and encapsulation
While there are many thousands of details in any given analysis, the reason to create a workflow is to structure all of those details so that they are understandable and traceable. Being explicit about dependencies and building a hierarchical workflow that encapsulates the steps of the work as independent modules. So the idea is to focus the workflow on the major steps in the pipeline, and to articulate each of their dependencies.
Workflows can be implemented in many ways, with various benefits:
- as a conceptual diagram
- As a series of functions that perform each step through a controlling script
- As a series functions managed by a workflow tool like
targets - many others…
Here’s a simple, toy example of using functions to encapsulate a workflow.
load_data <- function() {
delta_taxa_file <- contentid::resolve("hash://sha256/1473de800f3c5577da077507fb006be816a9194ddd417b1b98836be92eaea49d")
delta_taxa <- readr::read_csv(delta_taxa_file, show_col_types = FALSE)
print("Data loading complete.")
return(delta_taxa)
}
clean_data <- function(delta_taxa) {
print("Data cleaning not implemented yet.")
}
plot_data <- function(delta_taxa) {
print("Plotting not implemented yet.")
}
run_workflow <- function() {
delta_taxa <- load_data()
delta_taxa_cleaned <- clean_data(delta_taxa)
plot_data(delta_taxa_cleaned)
print("Worflow run completed.")
}
run_workflow()## [1] "Data loading complete."
## [1] "Data cleaning not implemented yet."
## [1] "Plotting not implemented yet."
## [1] "Worflow run completed."This workflow modularizes the code so that it is reasonably understandable, and it makes the dependencies among the steps clear. But we can do more. Each time the workflow is run, all of the functions are run. We could improve efficiency by only running the functions for which a dependencies changed.
Dependencies
Dependencies are the data and processes that must have completed before a given step in the workflow can be run. In purely functional programming, all of the dependencies would be passed as arguments to the function. This makes it so that the function is able to run with only the information that is passed to it at runtime, and is very powerful. However, dependendencies can also be provided by writing files to disk, or into a daatbase. These are called side effects, because a change in the state of the application was made (e.g., a file was changed), but there is no signal in the main function calls that this has happened. Many workflow systems are simply trying to make it easier to manage both direct dependencies and side-effects so that execution of a workflow can be executed cleanly.
6.1.4 Benefits
The benefits of conceptualizing work as a workflow include:
- Improved understanding
- Efficiency
- Automation
- Improved quality via modular testing
- Reproducibility
6.1.5 Organizing code in packages
Utilizing functions is key to good workflow design. We also need mechanisms to organize these functions so that they are accessible to a workflow executor. In the toy example above I put all of the functions in a single code block in a single function. While this works, it would get unwieldy in larger projects. While there are various ways to include code that is present in multiple files (e.g., using source), R Packages are specifically designed to make it easy to encapsulate work into different functions and files, and have those be accessible to all parts of the workflow. They also provide a great mechanism for describing the installation dependencies of your code. The basic structure of an R package is just a series of R code in files in the R subdirectory, with metadata about the package:
.
├── DESCRIPTION
├── LICENSE.md
├── NAMESPACE
├── R
│ └── load_data.R
│ └── load_data_taxa.R
│ └── load_data_catch.R
│ └── clean_taxa.R
│ └── environment_info.R
├── man
│ └── environment_info.Rd
├── mytools.Rproj
└── tests
├── testthat
│ └── test-enviroment_info.R
└── testthat.R6.1.6 Workflow systems
While managing workflows solely as linked functions works, the presence of side-effects in a workflow can make it more difficult to efficiently run only the parts of the workflow where items have changed. Workflow systems like Make and [targets] have been created to provide a structured way to specify, analyze, and track dependencies, and to execute only the parts of the workflow that are needed. For example, here’s an example workflow from targets:
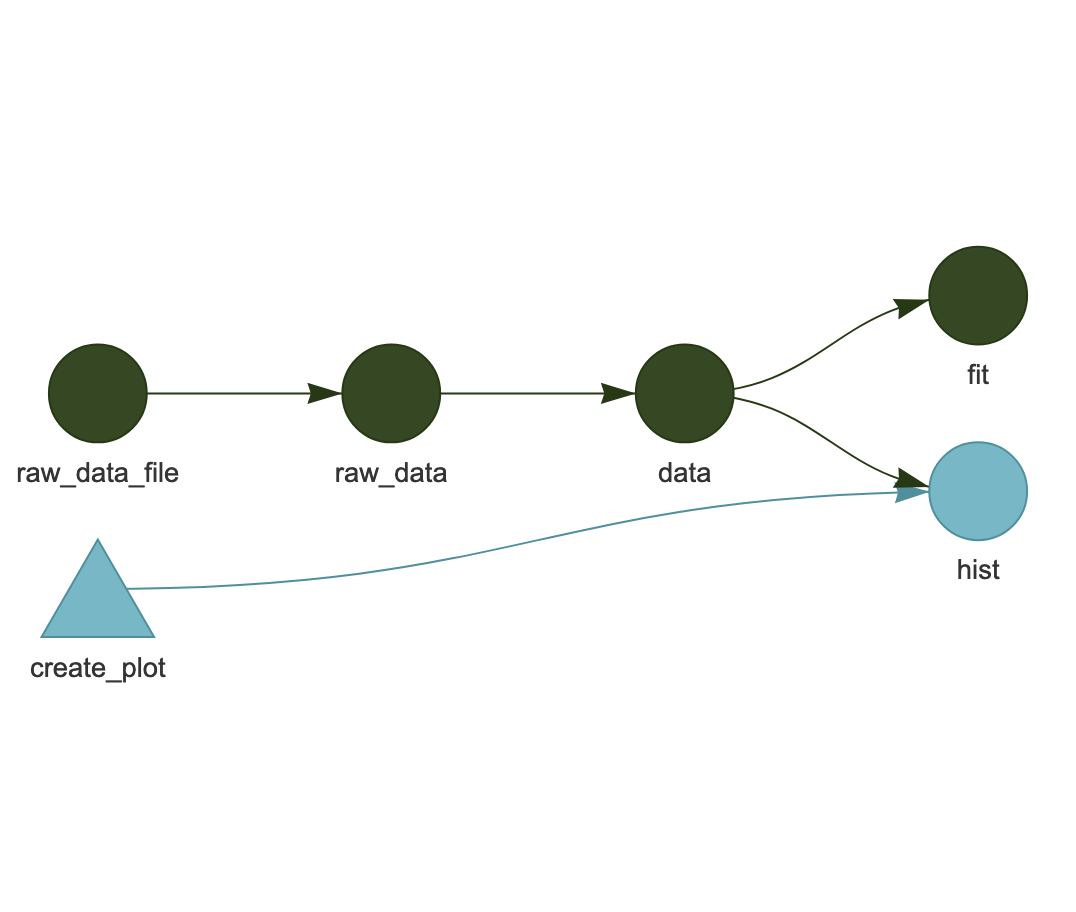
In this workflow, each icon represents a target state of the application, and it is the job of the workflow executor to make sure that all of these “targets” are up-to-date. The final products are dependent on both a pre-processed data pipeline, and on the code for generating a plot. In this example, the dark green icons indicate parts of the workflow that have not changed. Whereas the blue create_plot box indicates that the function has changed, which then “taints” all of the downstream parts of the workflow that depend on it. So, in this case, the change in create_plot means that the hist target must be re-executed, but the data processing pipeline above it does not currently need to be re-run.
Targets is configured by producing a special R script (_targets.R) that sets up the workflow to be executed. Here’s an example from the simple workflow example above:
library(targets)
library(tarchetypes)
source("R/functions.R")
options(tidyverse.quiet = TRUE)
tar_option_set(packages = c("biglm", "dplyr", "ggplot2", "readr", "tidyr"))
list(
tar_target(
raw_data_file,
"data/raw_data.csv",
format = "file"
),
tar_target(
raw_data,
read_csv(raw_data_file, col_types = cols())
),
tar_target(
data,
raw_data %>%
filter(!is.na(Ozone))
),
tar_target(hist, create_plot(data)),
tar_target(fit, biglm(Ozone ~ Wind + Temp, data)),
tar_render(report, "index.Rmd")
)This is really useful for being able to incrementally work through data loading and cleaning pipelines that feed downstream analytical functions that depend on using a consistent set of input data.
6.1.7 Exercise
Take an analysis that you are familiar with, and:
- draw a diagram of the major steps and substeps of the workflow
- analyze the dependencies of these steps and substeps
- stub out a set of functions that would execute that workflow
6.1.8 Readings and tutorials
- The
targetspackage
6.2 Parallel Computing in R
6.2.1 Learning Outcomes
- Understand what parallel computing is and when it may be useful
- Understand how parallelism can work
- Review sequential loops and *apply functions
- Understand and use the
parallelpackage multicore functions - Understand and use the
foreachpackage functions
6.2.2 Introduction
Processing large amounts of data with complex models can be time consuming. New types of sensing means the scale of data collection today is massive. And modeled outputs can be large as well. For example, here’s a 2 TB (that’s Terabyte) set of modeled output data from Ofir Levy et al. 2016 that models 15 environmental variables at hourly time scales for hundreds of years across a regular grid spanning a good chunk of North America:
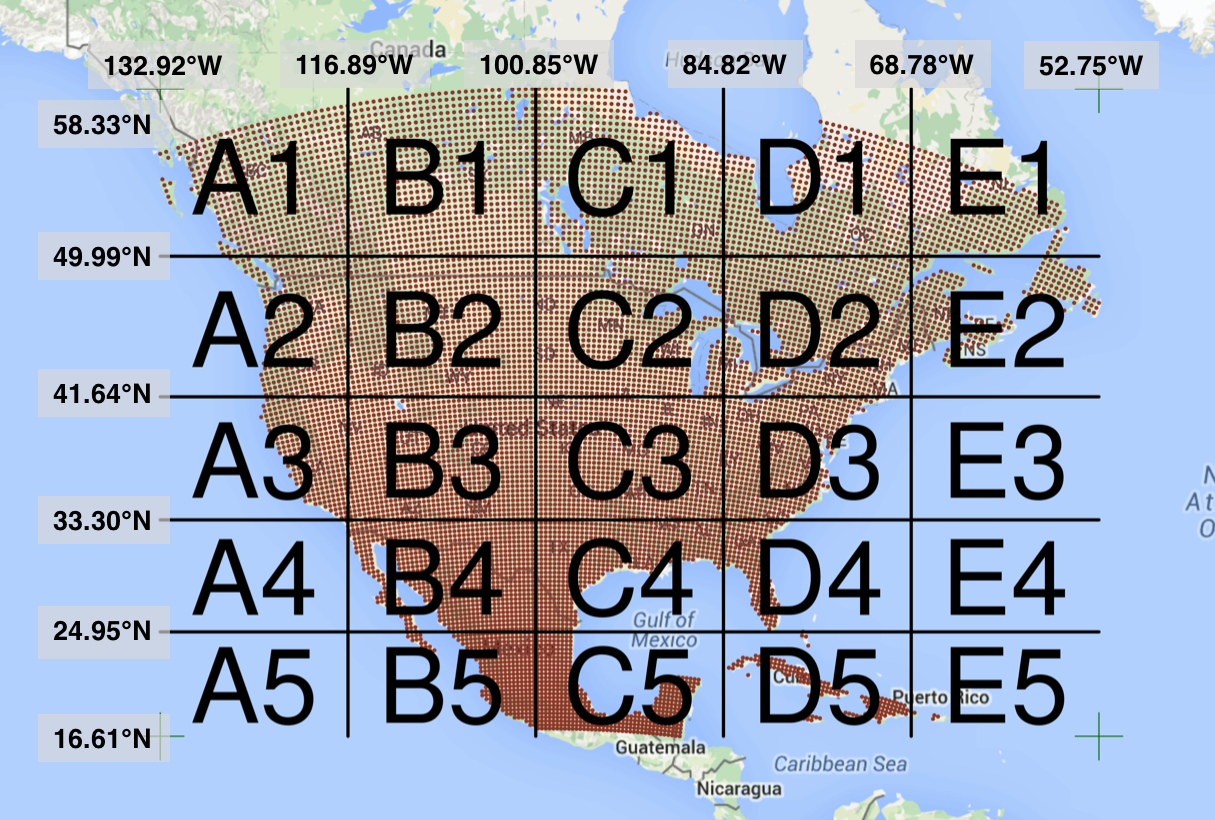
Levy et al. 2016. doi:10.5063/F1Z899CZ
There are over 400,000 individual netCDF files in the Levy et al. microclimate data set. Processing them would benefit massively from parallelization.
Alternatively, think of remote sensing data. Processing airborne hyperspectral data can involve processing each of hundreds of bands of data for each image in a flight path that is repeated many times over months and years.
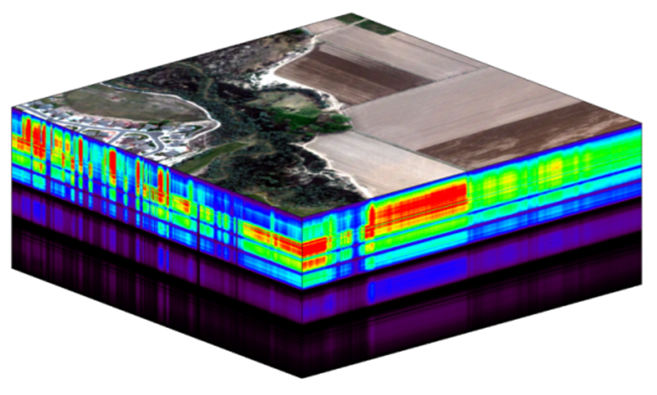
NEON Data Cube
6.2.3 Why parallelism?
Much R code runs fast and fine on a single processor. But at times, computations can be:
- cpu-bound: Take too much cpu time
- memory-bound: Take too much memory
- I/O-bound: Take too much time to read/write from disk
- network-bound: Take too much time to transfer
To help with cpu-bound computations, one can take advantage of modern processor architectures that provide multiple cores on a single processor, and thereby enable multiple computations to take place at the same time. In addition, some machines ship with multiple processors, allowing large computations to occur across the entire cluster of those computers. Plus, these machines also have large amounts of memory to avoid memory-bound computing jobs.
6.2.4 Processors (CPUs) and Cores
A modern CPU (Central Processing Unit) is at the heart of every computer. While traditional computers had a single CPU, modern computers can ship with mutliple processors, which in turn can each contain multiple cores. These processors and cores are available to perform computations.
A computer with one processor may still have 4 cores (quad-core), allowing 4 computations to be executed at the same time.
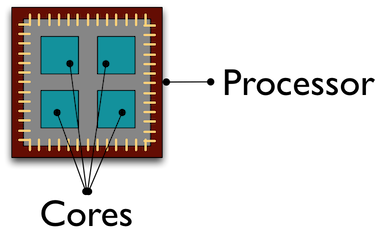
A typical modern computer has multiple cores, ranging from one or two in laptops to thousands in high performance compute clusters. Here we show four quad-core processors for a total of 16 cores in this machine.
You can think of this as allowing 16 computations to happen at the same time. Theroetically, your computation would take 1/16 of the time (but only theoretically, more on that later).
Historically, R has only utilized one processor, which makes it single-threaded. Which is a shame, because the 2017 MacBook Pro that I am writing this on is much more powerful than that:
jones@powder:~$ sysctl hw.ncpu hw.physicalcpu
hw.ncpu: 8
hw.physicalcpu: 4To interpret that output, this machine powder has 4 physical CPUs, each of which has
two processing cores, for a total of 8 cores for computation. I’d sure like my R computations to use all of that processing power. Because its all on one machine, we can easily use multicore processing tools to make use of those cores. Now let’s look at
the computational server aurora at NCEAS:
jones@aurora:~$ lscpu | egrep 'CPU\(s\)|per core|per socket'
CPU(s): 88
On-line CPU(s) list: 0-87
Thread(s) per core: 2
Core(s) per socket: 22
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63,65,67,69,71,73,75,77,79,81,83,85,87Now that’s some compute power! Aurora has 384 GB of RAM, and ample storage. All still under the control of a single operating system.
However, maybe one of these NSF-sponsored high performance computing clusters (HPC) is looking attractive about now:
- JetStream
- 640 nodes, 15,360 cores, 80TB RAM
- Stampede2 at TACC is coming online in 2017
- 4200 nodes, 285,600 cores
Note that these clusters have multiple nodes (hosts), and each host has multiple cores. So this is really multiple computers clustered together to act in a coordinated fashion, but each node runs its own copy of the operating system, and is in many ways independent of the other nodes in the cluster. One way to use such a cluster would be to use just one of the nodes, and use a multi-core approach to parallelization to use all of the cores on that single machine. But to truly make use of the whole cluster, one must use parallelization tools that let us spread out our computations across multiple host nodes in the cluster.
6.2.5 When to parallelize
It’s not as simple as it may seem. While in theory each added processor would linearly increase the throughput of a computation, there is overhead that reduces that efficiency. For example, the code and, importantly, the data need to be copied to each additional CPU, and this takes time and bandwidth. Plus, new processes and/or threads need to be created by the operating system, which also takes time. This overhead reduces the efficiency enough that realistic performance gains are much less than theoretical, and usually do not scale linearly as a function of processing power. For example, if the time that a computation takes is short, then the overhead of setting up these additional resources may actually overwhelm any advantages of the additional processing power, and the computation could potentially take longer!
In addition, not all of a task can be parallelized. Depending on the proportion, the expected speedup can be significantly reduced. Some propose that this may follow Amdahl’s Law, where the speedup of the computation (y-axis) is a function of both the number of cores (x-axis) and the proportion of the computation that can be parallelized (see colored lines):
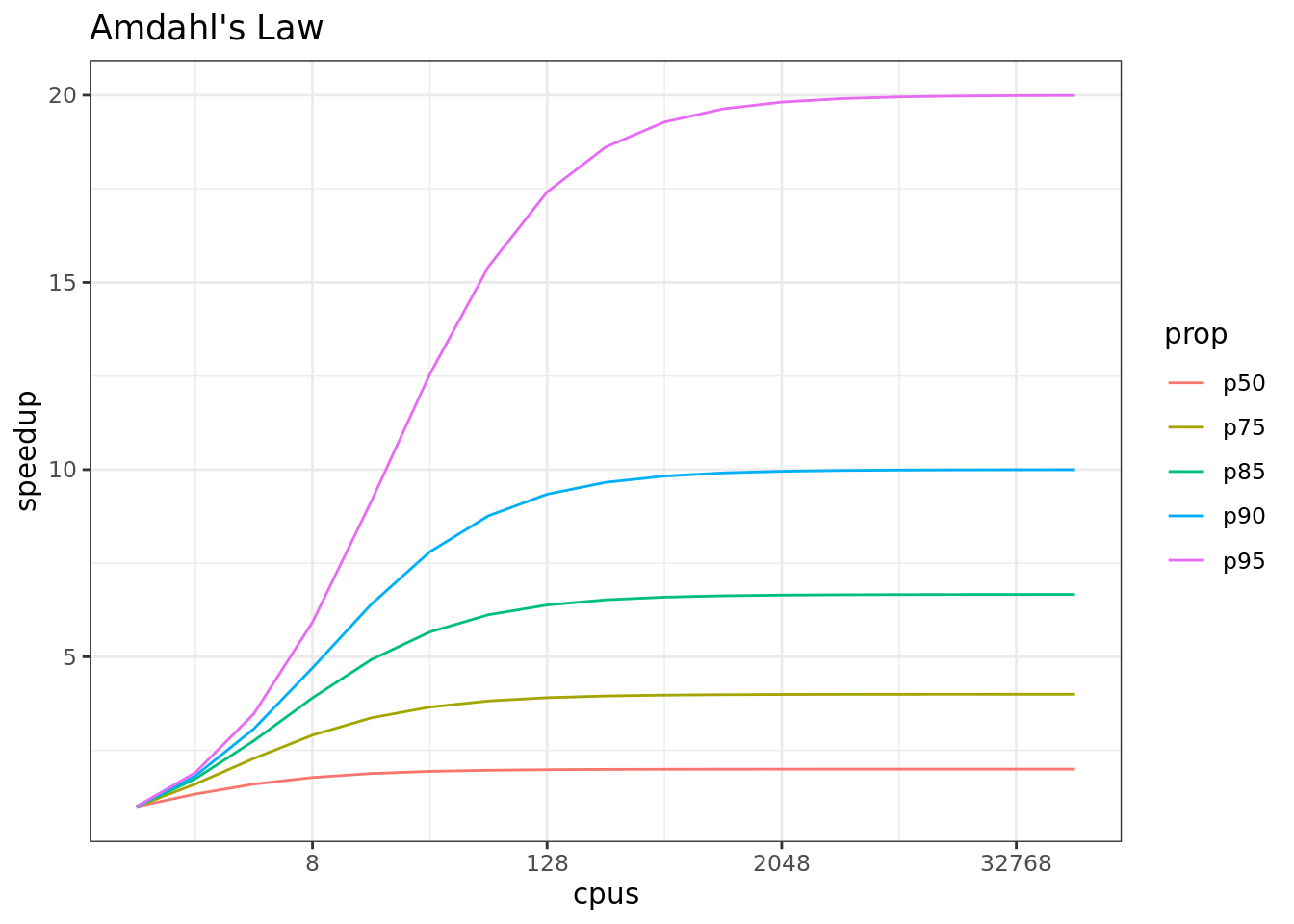
So, its important to evaluate the computational efficiency of requests, and work to ensure that additional compute resources brought to bear will pay off in terms of increased work being done. With that, let’s do some parallel computing…
6.2.6 Loops and repetitive tasks using lapply
When you have a list of repetitive tasks, you may be able to speed it up by adding more computing power. If each task is completely independent of the others, then it is a prime candidate for executing those tasks in parallel, each on its own core. For example, let’s build a simple loop that uses sample with replacement to do a bootstrap analysis. In this case, we select Sepal.Length and Species from the iris dataset, subset it to 100 observations, and then iterate across 10,000 trials, each time resampling the observations with replacement. We then run a logistic regression fitting species as a function of length, and record the coefficients for each trial to be returned.
x <- iris[which(iris[,5] != "setosa"), c(1,5)]
trials <- 10000
res <- data.frame()
system.time({
trial <- 1
while(trial <= trials) {
ind <- sample(100, 100, replace=TRUE)
result1 <- glm(x[ind,2]~x[ind,1], family=binomial(logit))
r <- coefficients(result1)
res <- rbind(res, r)
trial <- trial + 1
}
})## user system elapsed
## 21.220 0.694 21.843The issue with this loop is that we execute each trial sequentially, which means that only one of our 8 processors on this machine are in use. In order to exploit parallelism, we need to be able to dispatch our tasks as functions, with one task
going to each processor. To do that, we need to convert our task to a function, and then use the *apply() family of R functions to apply that function to all of the members of a set. In R, using apply used to be faster than the equivalent code in a loop, but now they are similar due to optimizations in R loop handling. However, using the function allows us to later take advantage of other approaches to parallelization. Here’s the same code rewritten to use lapply(), which applies a function to each of the members of a list (in this case the trials we want to run):
x <- iris[which(iris[,5] != "setosa"), c(1,5)]
trials <- seq(1, 10000)
boot_fx <- function(trial) {
ind <- sample(100, 100, replace=TRUE)
result1 <- glm(x[ind,2]~x[ind,1], family=binomial(logit))
r <- coefficients(result1)
res <- rbind(data.frame(), r)
}
system.time({
results <- lapply(trials, boot_fx)
})## user system elapsed
## 23.2 0.0 23.26.2.7 Approaches to parallelization
When parallelizing jobs, one can:
Use the multiple cores on a local computer through
mclapplyUse multiple processors on local (and remote) machines using
makeClusterandclusterApply- In this approach, one has to manually copy data and code to each cluster member using
clusterExport - This is extra work, but sometimes gaining access to a large cluster is worth it
- In this approach, one has to manually copy data and code to each cluster member using
6.2.8 Parallelize using: mclapply
The parallel library can be used to send tasks (encoded as function calls) to each of the processing cores on your machine in parallel. This is done by using the parallel::mclapply function, which is analogous to lapply, but distributes the tasks to multiple processors. mclapply gathers up the responses from each of these function calls, and returns a list of responses that is the same length as the list or vector of input data (one return per input item).
library(parallel)
library(MASS)##
## Attaching package: 'MASS'## The following object is masked from 'package:dplyr':
##
## selectstarts <- rep(100, 40)
fx <- function(nstart) kmeans(Boston, 4, nstart=nstart)
numCores <- detectCores()
numCores## [1] 24system.time(
results <- lapply(starts, fx)
)## user system elapsed
## 1.083 0.036 1.119system.time(
results <- mclapply(starts, fx, mc.cores = numCores)
)## user system elapsed
## 1.401 4.014 0.896Now let’s demonstrate with our bootstrap example:
x <- iris[which(iris[,5] != "setosa"), c(1,5)]
trials <- seq(1, 10000)
boot_fx <- function(trial) {
ind <- sample(100, 100, replace=TRUE)
result1 <- glm(x[ind,2]~x[ind,1], family=binomial(logit))
r <- coefficients(result1)
res <- rbind(data.frame(), r)
}
system.time({
results <- mclapply(trials, boot_fx, mc.cores = numCores)
})## user system elapsed
## 28.01 80.71 5.546.2.9 Parallelize using: foreach and doParallel
The normal for loop in R looks like:
for (i in 1:3) {
print(sqrt(i))
}## [1] 1
## [1] 1.41
## [1] 1.73The foreach method is similar, but uses the sequential %do% operator to indicate an expression to run. Note the difference in the returned data structure.
library(foreach)
foreach (i=1:3) %do% {
sqrt(i)
}## [[1]]
## [1] 1
##
## [[2]]
## [1] 1.41
##
## [[3]]
## [1] 1.73In addition, foreach supports a parallelizable operator %dopar% from the doParallel package. This allows each iteration through the loop to use different cores or different machines in a cluster. Here, we demonstrate with using all the cores on the current machine:
library(foreach)
library(doParallel)## Loading required package: iteratorsregisterDoParallel(numCores) # use multicore, set to the number of our cores
foreach (i=1:3) %dopar% {
sqrt(i)
}## [[1]]
## [1] 1
##
## [[2]]
## [1] 1.41
##
## [[3]]
## [1] 1.73# To simplify output, foreach has the .combine parameter that can simplify return values
# Return a vector
foreach (i=1:3, .combine=c) %dopar% {
sqrt(i)
}## [1] 1.00 1.41 1.73# Return a data frame
foreach (i=1:3, .combine=rbind) %dopar% {
sqrt(i)
}## [,1]
## result.1 1.00
## result.2 1.41
## result.3 1.73The doParallel vignette on CRAN shows a much more realistic example, where one can use `%dopar% to parallelize a bootstrap analysis where a data set is resampled 10,000 times and the analysis is rerun on each sample, and then the results combined:
# Let's use the iris data set to do a parallel bootstrap
# From the doParallel vignette, but slightly modified
x <- iris[which(iris[,5] != "setosa"), c(1,5)]
trials <- 10000
system.time({
r <- foreach(icount(trials), .combine=rbind) %dopar% {
ind <- sample(100, 100, replace=TRUE)
result1 <- glm(x[ind,2]~x[ind,1], family=binomial(logit))
coefficients(result1)
}
})## user system elapsed
## 23.38 10.85 3.14# And compare that to what it takes to do the same analysis in serial
system.time({
r <- foreach(icount(trials), .combine=rbind) %do% {
ind <- sample(100, 100, replace=TRUE)
result1 <- glm(x[ind,2]~x[ind,1], family=binomial(logit))
coefficients(result1)
}
})## user system elapsed
## 21.207 0.009 21.226# When you're done, clean up the cluster
stopImplicitCluster()6.2.10 Summary
In this lesson, we showed examples of computing tasks that are likely limited by the number of CPU cores that can be applied, and we reviewed the architecture of computers to understand the relationship between CPU processors and cores. Next, we reviewed the way in which traditional for loops in R can be rewritten as functions that are applied to a list serially using lapply, and then how the parallel package mclapply function can be substituted in order to utilize multiple cores on the local computer to speed up computations. Finally, we installed and reviewed the use of the foreach package with the %dopar operator to accomplish a similar parallelization using multiple cores.
6.2.11 Readings and tutorials
- Multicore Data Science with R and Python
- Beyond Single-Core R by Jonoathan Dursi (also see GitHub repo for slide source)
- The venerable Parallel R by McCallum and Weston (a bit dated on the tooling, but conceptually solid)
- The doParallel Vignette