1.1 Introduction to the Arctic Data Center and NSF Standards and Policies
1.1.1 Learning Objectives
In this lesson, we will discuss:
- The mission and structure of the Arctic Data Center
- How the Arctic Data Center supports the research community
- About data policies from the NSF Arctic program
1.1.2 Arctic Data Center - History and Introduction
The Arctic Data Center is the primary data and software repository for the Arctic section of National Science Foundation’s Office of Polar Programs (NSF OPP).
We’re best known in the research community as a data archive – researchers upload their data to preserve it for the future and make it available for re-use. This isn’t the end of that data’s life, though. These data can then be downloaded for different analyses or synthesis projects. In addition to being a data discovery portal, we also offer top-notch tools, support services, and training opportunities. We also provide data rescue services.
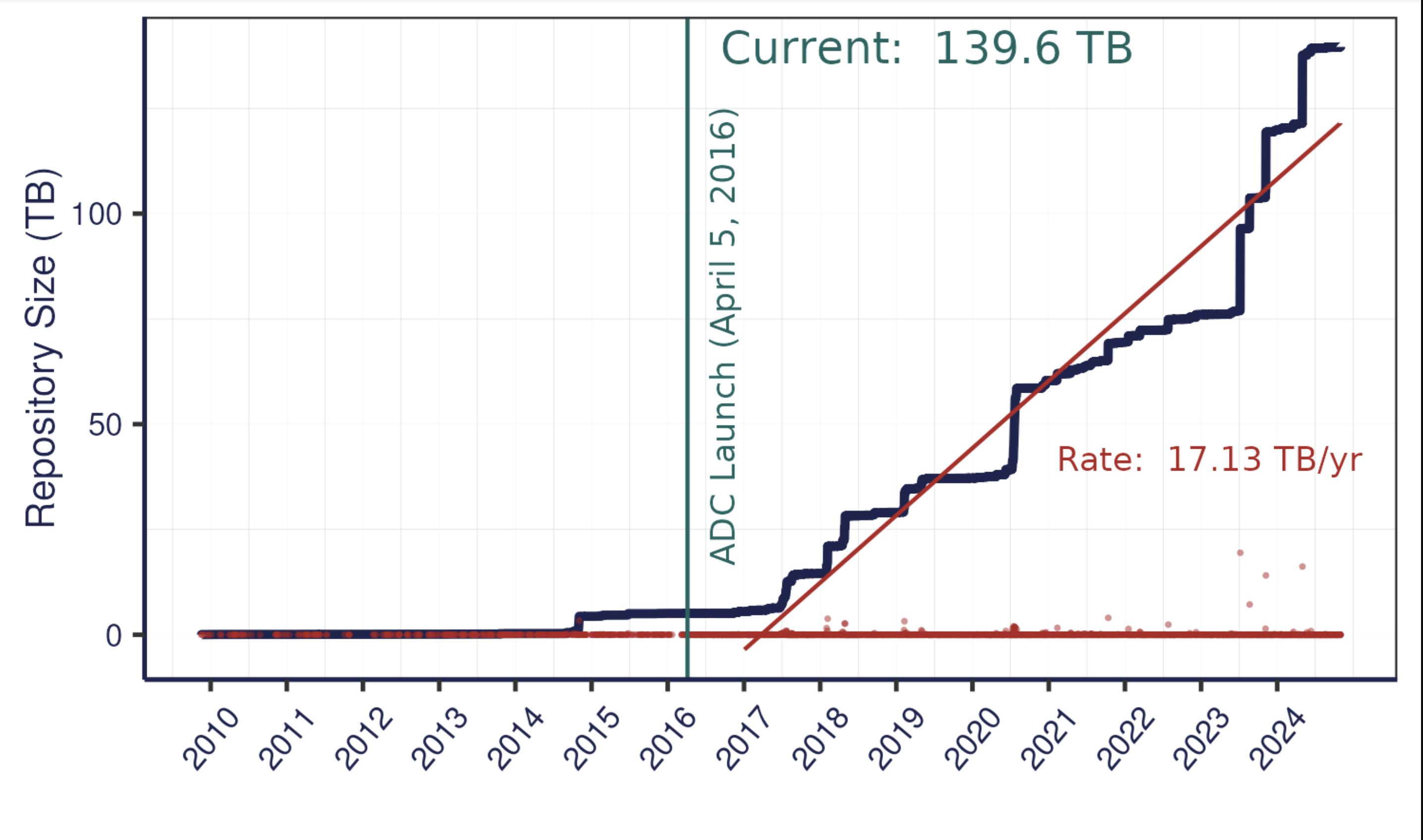
NSF has long had a commitment to data reuse and sharing. Since our start in 2016, we’ve grown substantially – from that original 4 TB of data from ACADIS to now over 140 TB towards the end of 2024. In 2021 alone, we saw 16% growth in dataset count, and about 30% growth in data volume. This increase has come from advances in tools – both ours and of the scientific community, plus active community outreach and a strong culture of data preservation from NSF and from researchers. We plan to add more storage capacity in the coming months, as researchers are coming to us with datasets in the terabytes, and we’re excited to preserve these research products in our archive. We’re projecting our growth to be around several hundred TB this year, which has a big impact on processing time. Give us a heads up if you’re planning on having larger submissions so that we can work with you and be prepared for a large influx of data.
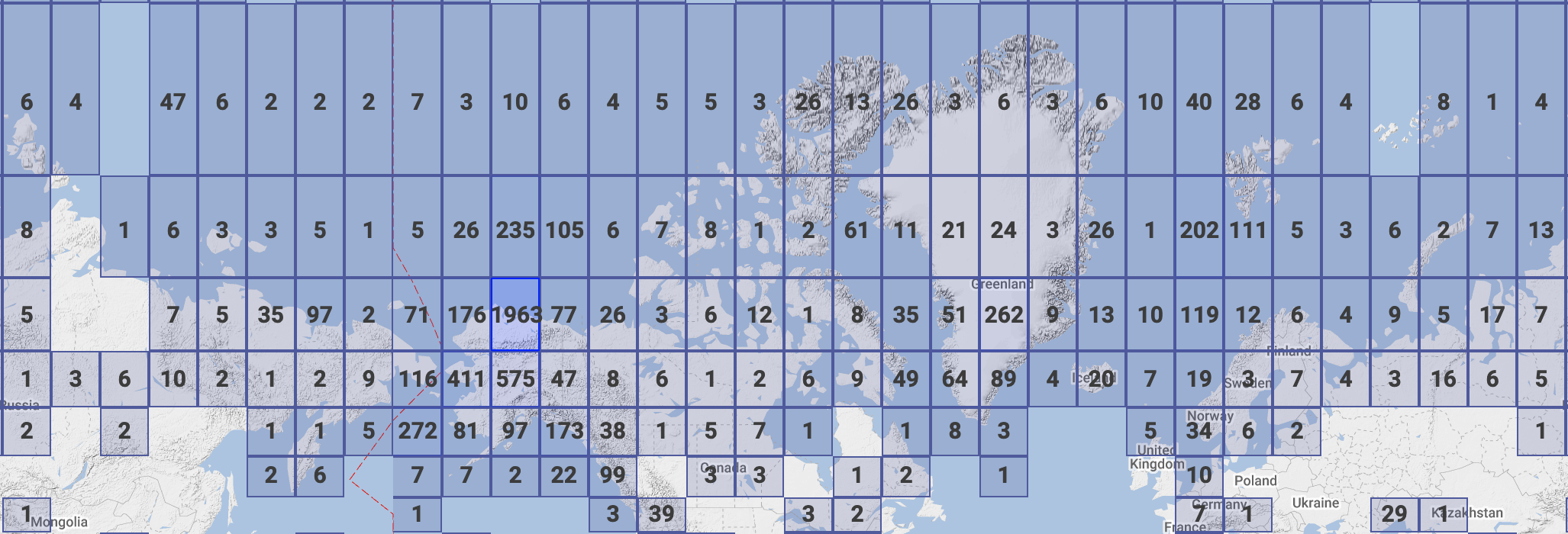
The data that we have in the Arctic Data Center comes from a wide variety of disciplines. These different programs within NSF all have different focuses – the Arctic Observing Network supports scientific and community-based observations of biodiversity, ecosystems, human societies, land, ice, marine and freshwater systems, and the atmosphere as well as their social, natural, and/or physical environments, so that encompasses a lot right there in just that one program. We’re also working on a way right now to classify the datasets by discipline, so keep an eye out for that coming soon.
.jpg)
Along with that diversity of disciplines comes a diversity of file types. The most common file type we have are image files in four different file types. Probably less than 200-300 of the datasets have the majority of those images – we have some large datasets that have image and/or audio files from drones. Most of those 6600+ datasets are tabular datasets. There’s a large diversity of data files, though, whether you want to look at remote sensing images, listen to passive acoustic audio files, or run applications – or something else entirely. We also cover a long period of time, at least by human standards. The data represented in our repository spans across centuries.

We also have data that spans the entire Arctic, as well as the sub-Arctic, regions.
1.1.3 Data Discovery Portal
To browse the data catalog, navigate to arcticdata.io. Go to the top of the page and under data, go to search. Right now, you’re looking at the whole catalog. You can narrow your search down by the map area, a general search, or searching by an attribute.
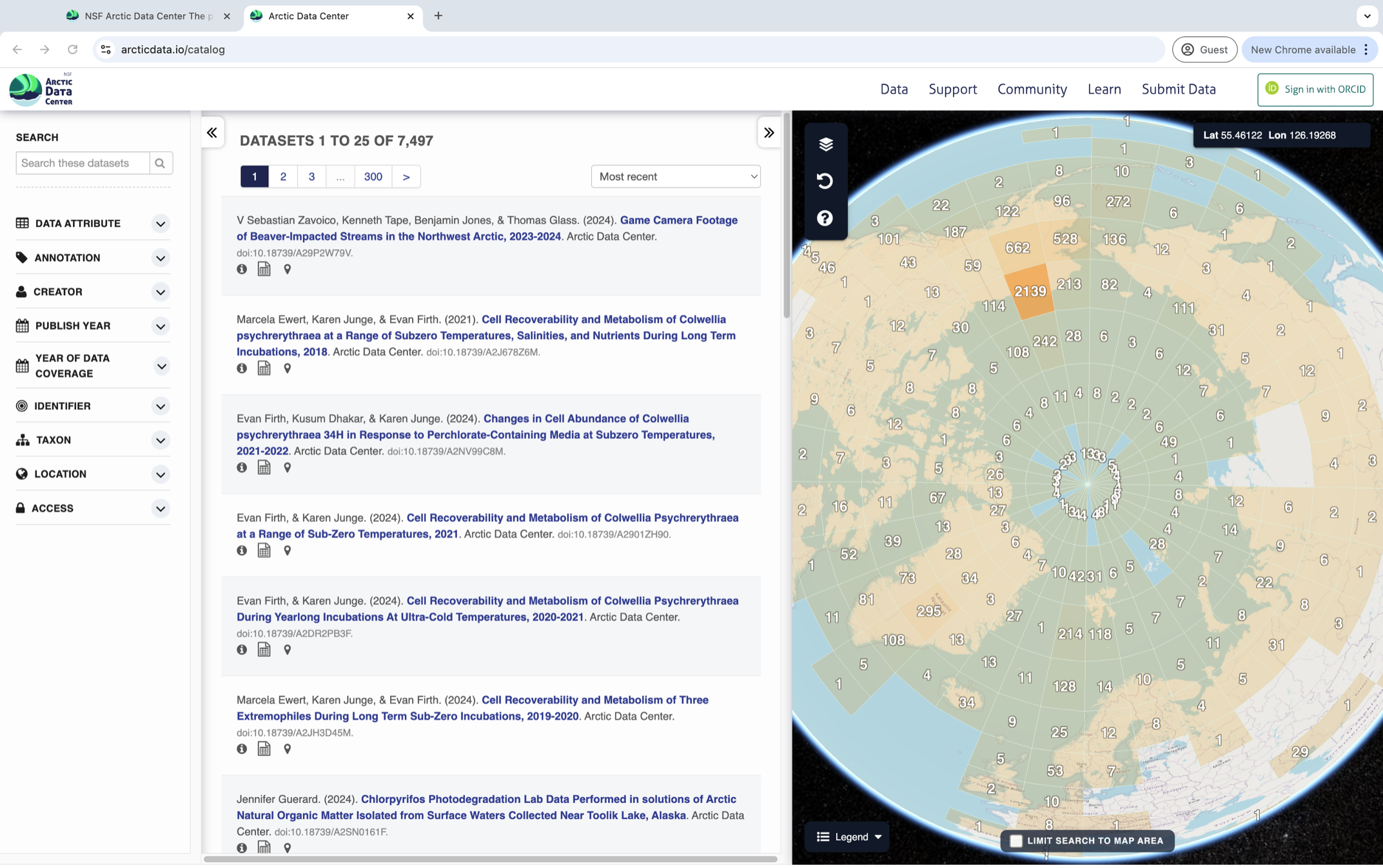 Clicking on a dataset brings you to this page. You have the option to download all the files by clicking the green “Download All” button, which will zip together all the files in the dataset to your Downloads folder. You can also pick and choose to download just specific files.
Clicking on a dataset brings you to this page. You have the option to download all the files by clicking the green “Download All” button, which will zip together all the files in the dataset to your Downloads folder. You can also pick and choose to download just specific files.
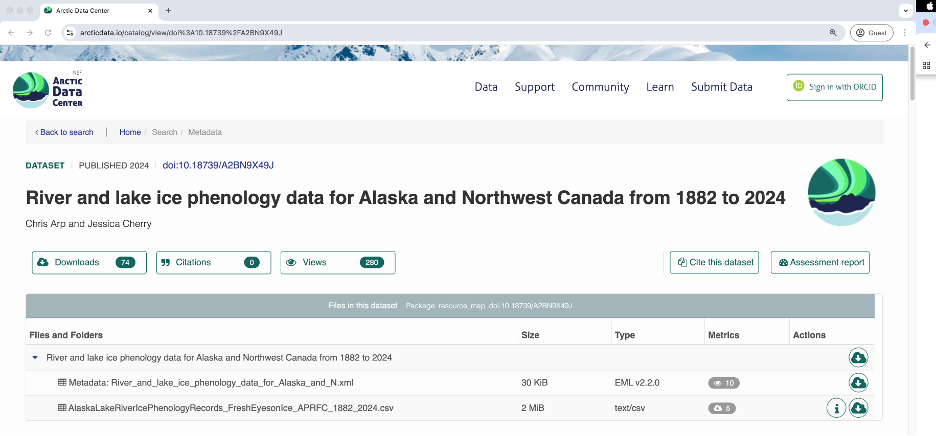
All the raw data is in open formats to make it easily accessible and compliant with FAIR principles – for example, tabular documents are in .csv (comma separated values) rather than Excel documents.
The metrics at the top give info about the number of citations with this data, the number of downloads, and the number of views. This is what it looks like when you click on the Downloads tab for more information.
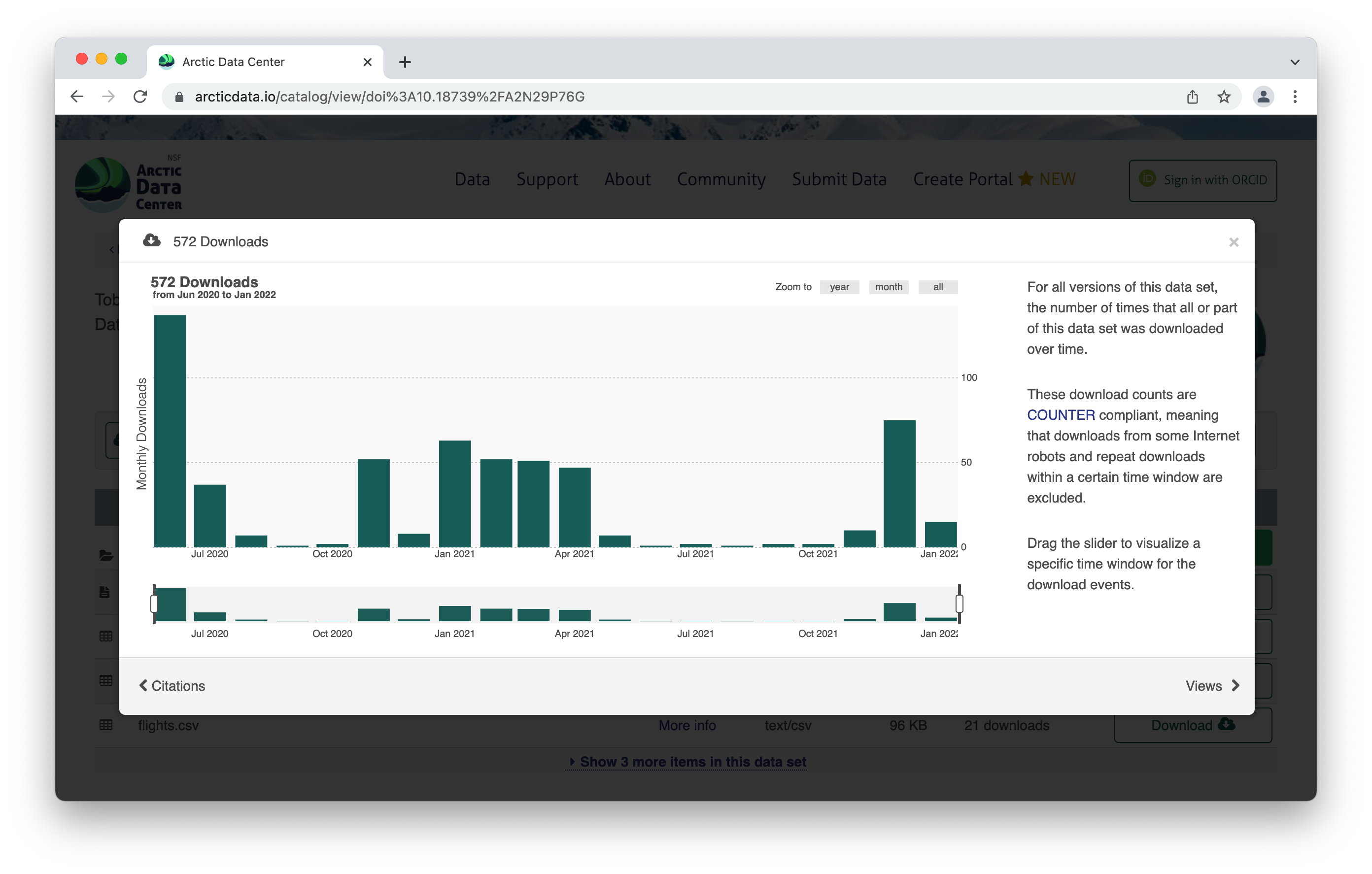
Scroll down for more info about the dataset – abstract, keywords. Then you’ll see more info about the data itself. This shows the data with a description, as well as info about the attributes (or variables or parameters) that were measured. The green check mark indicates that those attributes have been annotated, which means the measurements have a precise definition to them. Scrolling further, we also see who collected the data, where they collected it, and when they collected it, as well as any funding information like a grant number. For biological data, there is the option to add taxa.
1.1.4 Tools and Infrastructure
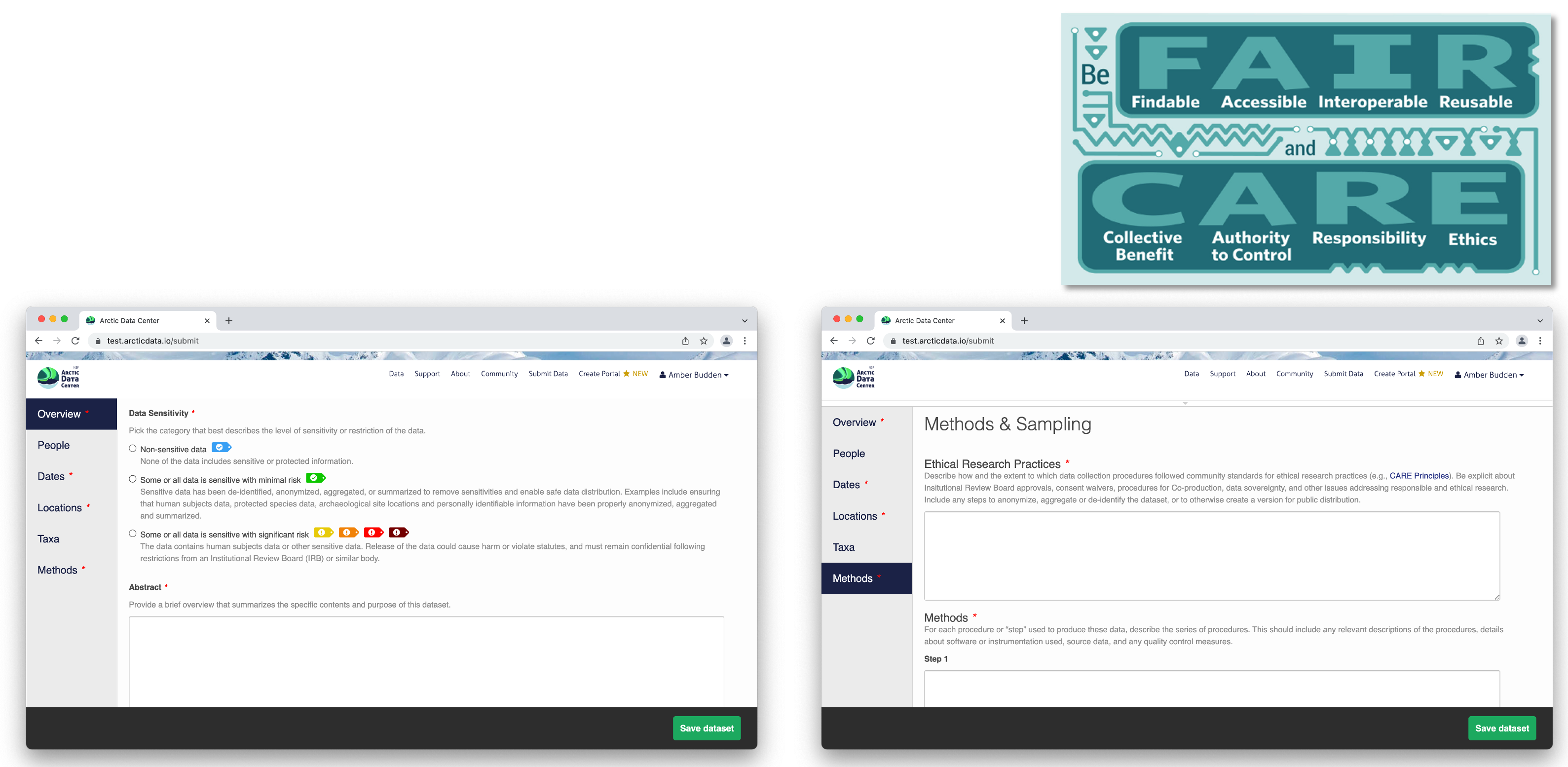
Across all our services and partnership, we are strongly aligned with the community principles of making data FAIR (Findable, Accesible, Interoperable and Reusable).
We have a number of tools available to submitters and researchers who are there to download data. We also partner with other organizations, like Make Data Count and DataONE, and leverage those partnerships to create a better data experience.

One of those tools is provenance tracking. With provenance tracking, users of the Arctic Data Center can see exactly what datasets led to what product, using the particular script that the researcher ran.
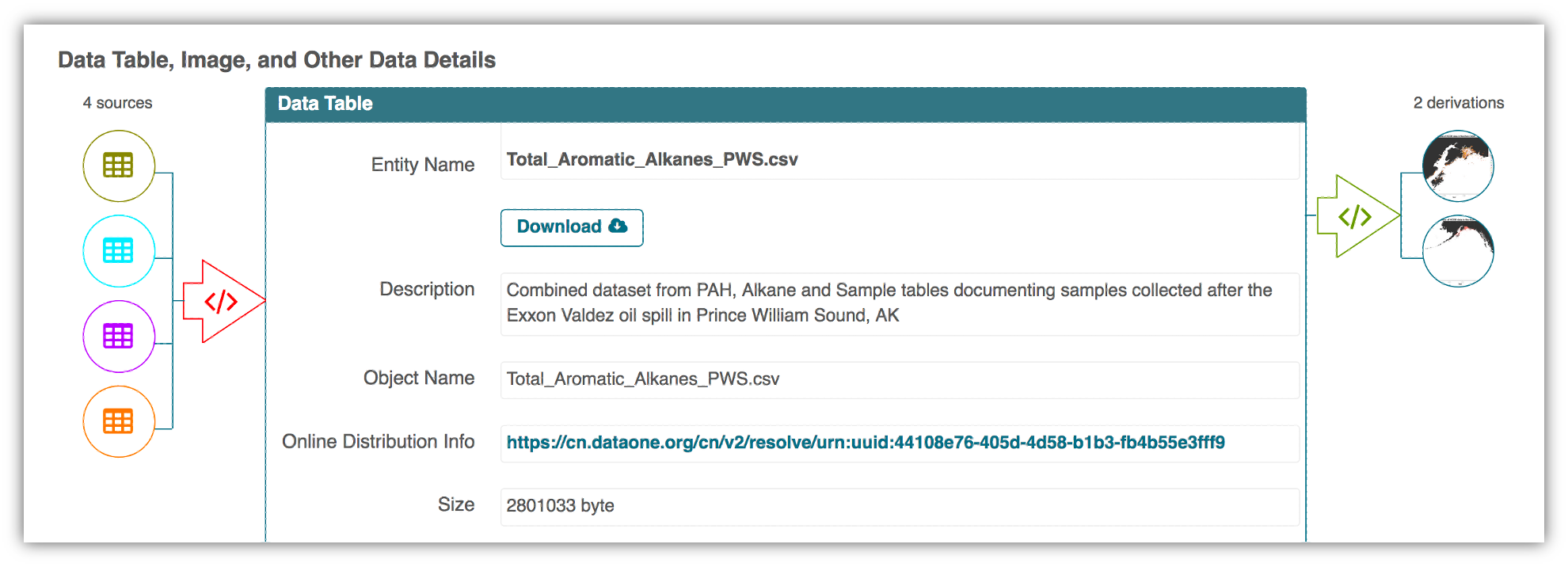
Another tool are our Metadata Quality Checks. We know that data quality is important for researchers to find datasets and to have trust in them to use them for another analysis. For every submitted dataset, the metadata is run through a quality check to increase the completeness of submitted metadata records. These checks are seen by the submitter as well as are available to those that view the data, which helps to increase knowledge of how complete their metadata is before submission. That way, the metadata that is uploaded to the Arctic Data Center is as complete as possible, and close to following the guideline of being understandable to any reasonable scientist.
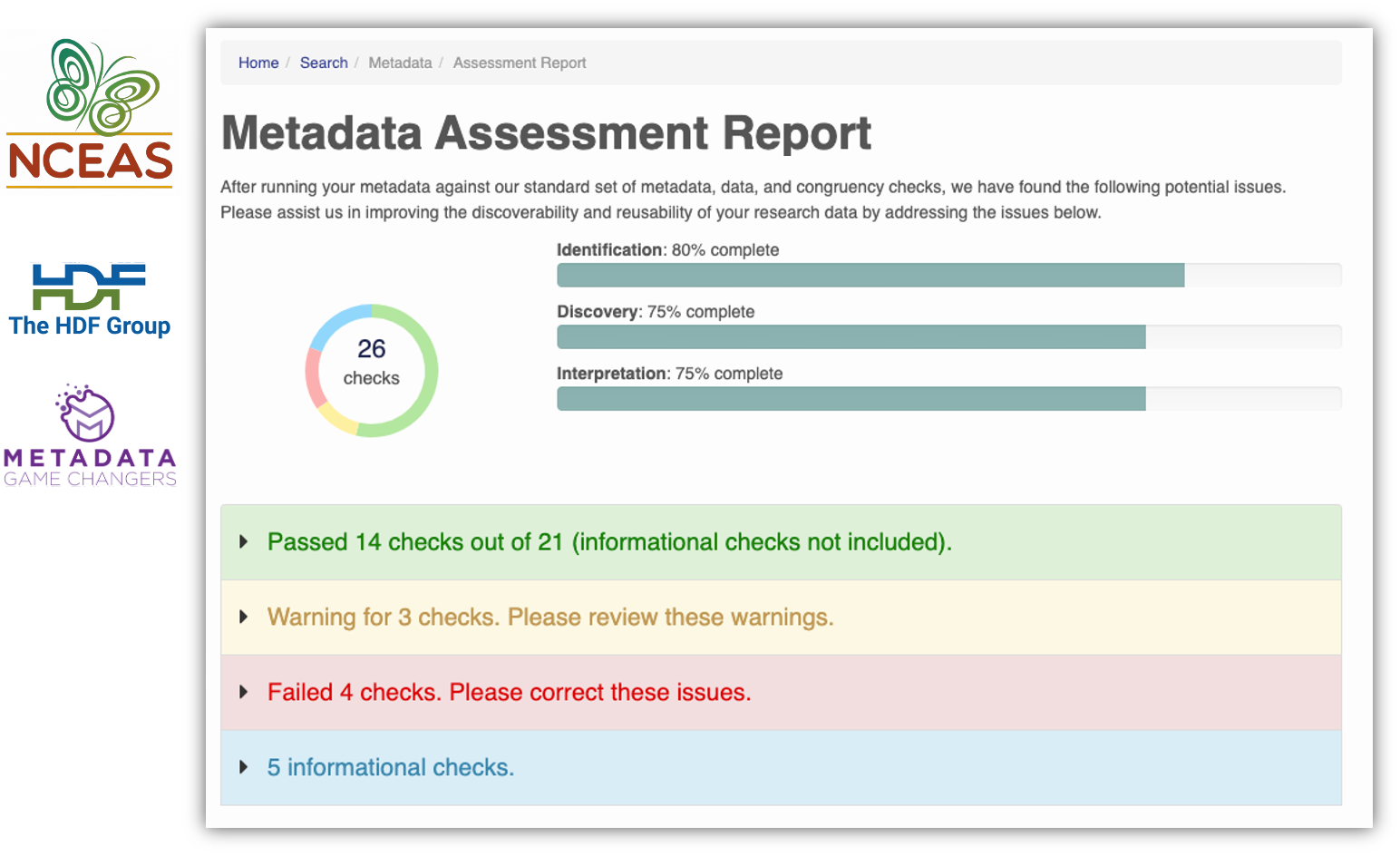
1.1.5 Support Services
Metadata quality checks are the automatic way that we ensure quality of data in the repository, but the real quality and curation support is done by our curation team. The process by which data gets into the Arctic Data Center is iterative, meaning that our team works with the submitter to ensure good quality and completeness of data. When a submitter submits data, our team gets a notification and beings to evaluate the data for upload. They then go in and format it for input into the catalog, communicating back and forth with the researcher if anything is incomplete or not communicated well. This process can take anywhere from a few days or a few weeks, depending on the size of the dataset and how quickly the researcher gets back to us. Once that process has been completed, the dataset is published with a DOI (digital object identifier).
1.1.6 Training and Outreach
In addition to the tools and support services, we also interact with the community via trainings like this one and outreach events. We run workshops at conferences like the American Geophysical Union, Arctic Science Summit Week and others. We also run an intern and fellows program, and webinars with different organizations. We’re invested in helping the Arctic science community learn reproducible techniques, since it facilitates a more open culture of data sharing and reuse.

We strive to keep our fingers on the pulse of what researchers like yourselves are looking for in terms of support. We’re active on Twitter and BlueSky to share Arctic updates, data science updates, and specifically Arctic Data Center updates, but we’re also happy to feature new papers or successes that you all have had with working with the data. We can also take data science questions if you’re running into those in the course of your research, or how to make a quality data management plan. Follow us on our media platforms and interact with us – we love to be involved in your research as it’s happening as well as after it’s completed.
1.1.7 Data Rescue
We also run data rescue operations. We digitized Autin Post’s collection of glacier photos that were taken from 1964 to 1997. There were 100,000+ files and almost 5 TB of data to ingest, and we reconstructed flight paths, digitized the images of his notes, and documented image metadata, including the camera specifications.

1.1.8 Who Must Submit
Projects that have to submit their data include all Arctic Research Opportunities through the NSF Office of Polar Programs. That data has to be uploaded within two years of collection. The Arctic Observing Network has a shorter timeline – their data products must be uploaded within 6 months of collection. Additionally, we have social science data, though that data often has special exceptions due to sensitive human subjects data. At the very least, the metadata has to be deposited with us.
Arctic Research Opportunities (ARC)
- Complete metadata and all appropriate data and derived products
- Within 2 years of collection or before the end of the award, whichever comes first
ARC Arctic Observation Network (AON)
- Complete metadata and all data
- Real-time data made public immediately
- Within 6 months of collection
Arctic Social Sciences Program (ASSP)
- NSF policies include special exceptions for ASSP and other awards that contain sensitive data
- Human subjects, governed by an Institutional Review Board, ethically or legally sensitive, at risk of decontextualization
- Metadata record that documents non-sensitive aspects of the project and data
- Title, Contact information, Abstract, Methods
For more complete information see our “Who Must Submit” webpage
Recognizing the importance of sensitive data handling and of ethical treatment of all data, the Arctic Data Center submission system provides the opportunity for researchers to document the ethical treatment of data and how collection is aligned with community principles (such as the CARE principles). Submitters may also tag the metadata according to community develop data sensitivity tags. We will go over these features in more detail shortly.
1.1.9 Summary
All the above informtion can be found on our website or if you need help, ask our support team at support@arcticdata.io or tweet us @arcticdatactr!

Learning Objectives
- Practice creating an R Project
- Organize an R Project for effective project management
- Understand how to move in an R Project using paths and working directories
1.2 Logon to the RStudio Server
To prevent us from spending most of this lesson troubleshooting the myriad of issues that can arise when setting up the R, RStudio, and git environments, we have chosen to have everyone work on a remote server with all of the software you need installed. We will be using a special kind of RStudio just for servers called RStudio Server. If you have never worked on a remote server before, you can think of it like working on a different computer via the internet. Note that the server has no knowledge of the files on your local filesystem, but it is easy to transfer files from the server to your local computer, and vice-versa, using the RStudio server interface.
You should have received an email prompting you to change your password for your server account. If you did not, please put up a post-it and someone will help you.
After you have successfully changed your password log in at: https://included-crab.nceas.ucsb.edu/
1.3 Create an R Project
In this course, we are going to be using an R project to organize our work. An R project is tied to a directory on your local computer, and makes organizing your work and collaborating with others easier.
The Big Idea: using an R project is a reproducible research best practice because it bundles all your work within a working directory. Consider your current data analysis workflow. Where do you import you data? Where do you clean and wrangle it? Where do you create graphs, and ultimately, a final report? Are you going back and forth between multiple software tools like Microsoft Excel, JMP, and Google Docs? An R project and the tools in R that we will talk about today will consolidate this process because it can all be done (and updated) in using one software tool, RStudio, and within one R project.
1.4 Organizing an R Project
When starting a new research project, one of the first things I do is create an R Project for it (just like we have here!). The next step is to then populate that project with relevant directories. There are many tools out there that can do this automatically. Some examples are rrtools or usethis::create_package(). The goal is to organize your project so that it is a compendium of your research. This means that the project has all of the digital parts needed to replicate your analysis, like code, figures, the manuscript, and data access.
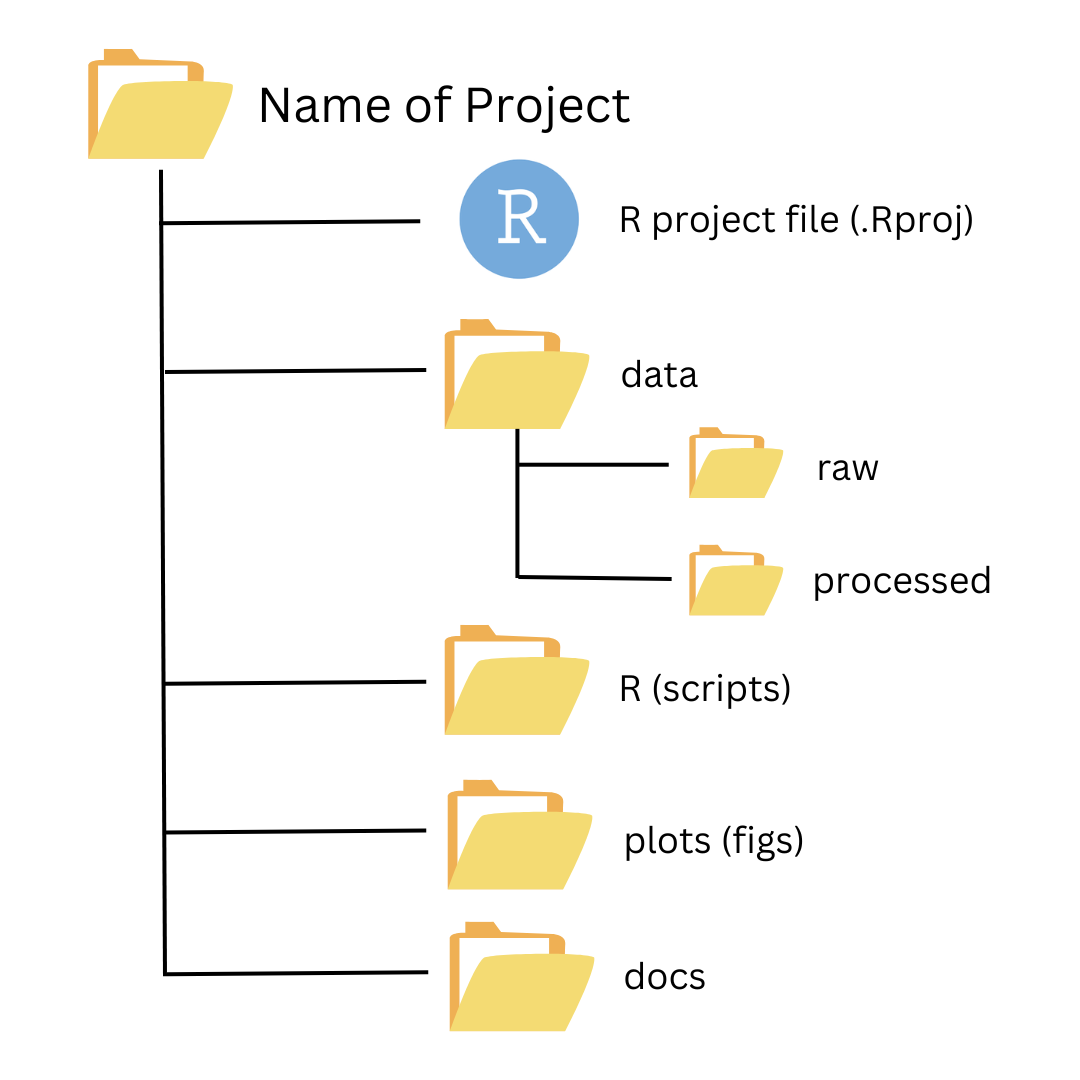
Some common directories are:
data: where we store our data (often contains subdirectories for raw, processed, and metadata data)R: contains scripts with your custom R functions, etc. (some find this name misleading if their work has other scripts beyond the R programming language, in which case they call this directoryscripts)plotsorfigs: generated plots, graphs, and figuresdocs: summaries or reports of analysis or other relevant project information
Directory organization will vary from project to project, but the ultimate goal is to create a well organized project for both reproducibility and collaboration.
1.5 Moving in an R Project using Paths & Working Directories
Now that we have your project created (and notice we know it’s an R Project because we see a .Rproj file in our Files pane), let’s learn how to move in a project. We do this using paths.
There are two types of paths in computing: absolute paths and relative paths.
An absolute path always starts with the root of your file system and locates files from there. The absolute path to my project directory is:
/home/vargas-poulsen/training_vargasRelative paths start from some location in your file system that is below the root. Relative paths are combined with the path of that location to locate files on your system. R (and some other languages like MATLAB) refer to the location where the relative path starts as our working directory.
RStudio projects automatically set the working directory to the directory of the project. This means that you can reference files from within the project without worrying about where the project directory itself is. If I want to read in a file from the data directory within my project, I can simply type read.csv("data/samples.csv") as opposed to read.csv("/home/vargas-poulsen/training_vargas/data/samples.csv").
This is not only convenient for you, but also when working collaboratively. We will talk more about this later, but if Matt makes a copy of my R project that I have published on GitHub, and I am using relative paths, he can run my code exactly as I have written it, without going back and changing /home/vargas-poulsen/training_vargas/data/samples.csv to /home/jones/training_jones/data/samples.csv.
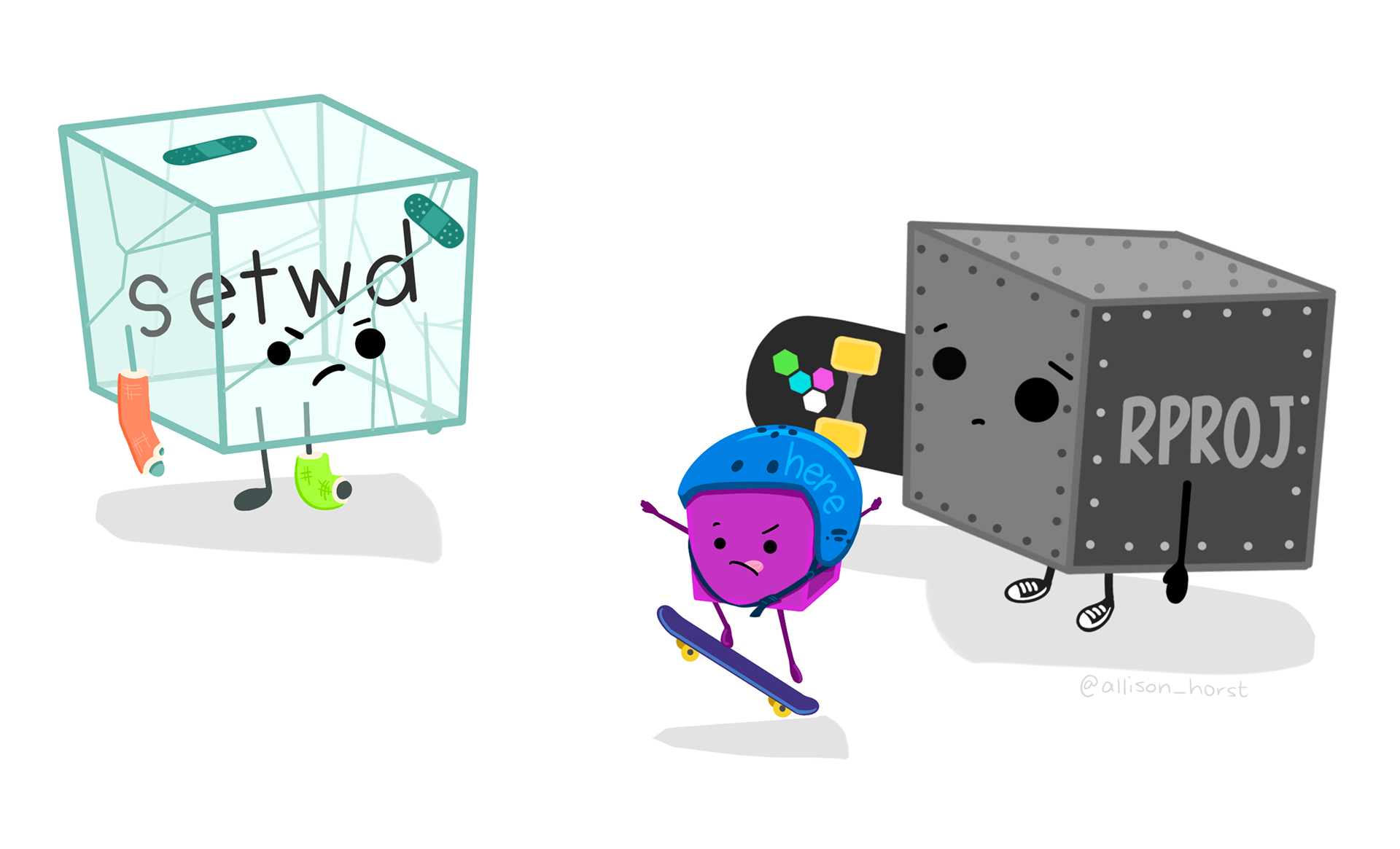
Note that once you start working in projects you should basically never need to run the setwd() command. If you are in the habit of doing this, stop and take a look at where and why you do it. Could leveraging the working directory concept of R projects eliminate this need? Almost definitely!
Similarly, think about how you work with absolute paths. Could you leverage the working directory of your R project to replace these with relative paths and make your code more portable? Probably!